commit
b6f591f696
126
compare.md
126
compare.md
@ -1,63 +1,63 @@
|
||||
# 对比本工具和其他类似工具在 server side copy 的速度上的差异
|
||||
|
||||
以拷贝[https://drive.google.com/drive/folders/1W9gf3ReGUboJUah-7XDg5jKXKl5XwQQ3](https://drive.google.com/drive/folders/1W9gf3ReGUboJUah-7XDg5jKXKl5XwQQ3)为例([文件统计](https://gdurl.viegg.com/api/gdrive/count?fid=1W9gf3ReGUboJUah-7XDg5jKXKl5XwQQ3))
|
||||
共 242 个文件和 26 个文件夹
|
||||
|
||||
如无特殊说明,以下运行环境都是在本地命令行(挂代理)
|
||||
|
||||
## 本工具耗时 40 秒
|
||||
<!-- 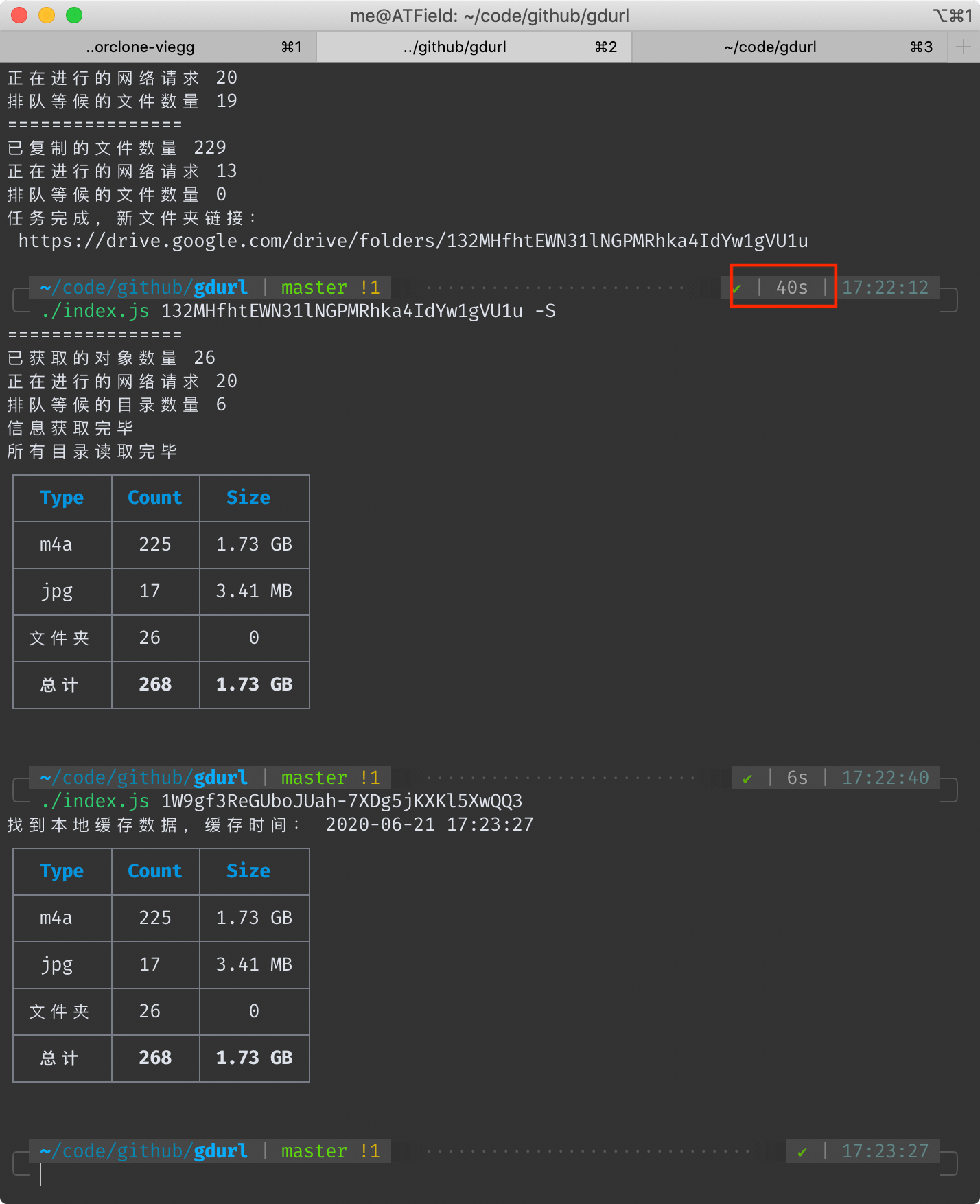 -->
|
||||

|
||||
|
||||
另外我在一台洛杉矶的vps上执行相同的命令,耗时23秒。
|
||||
这个速度是在使用本项目默认配置**20个并行请求**得出来的,此值可自行修改(下文有方法),并行请求数越大,总速度越快。
|
||||
|
||||
## AutoRclone 耗时 4 分 57 秒(去掉拷贝后验证时间 4 分 6 秒)
|
||||
<!-- 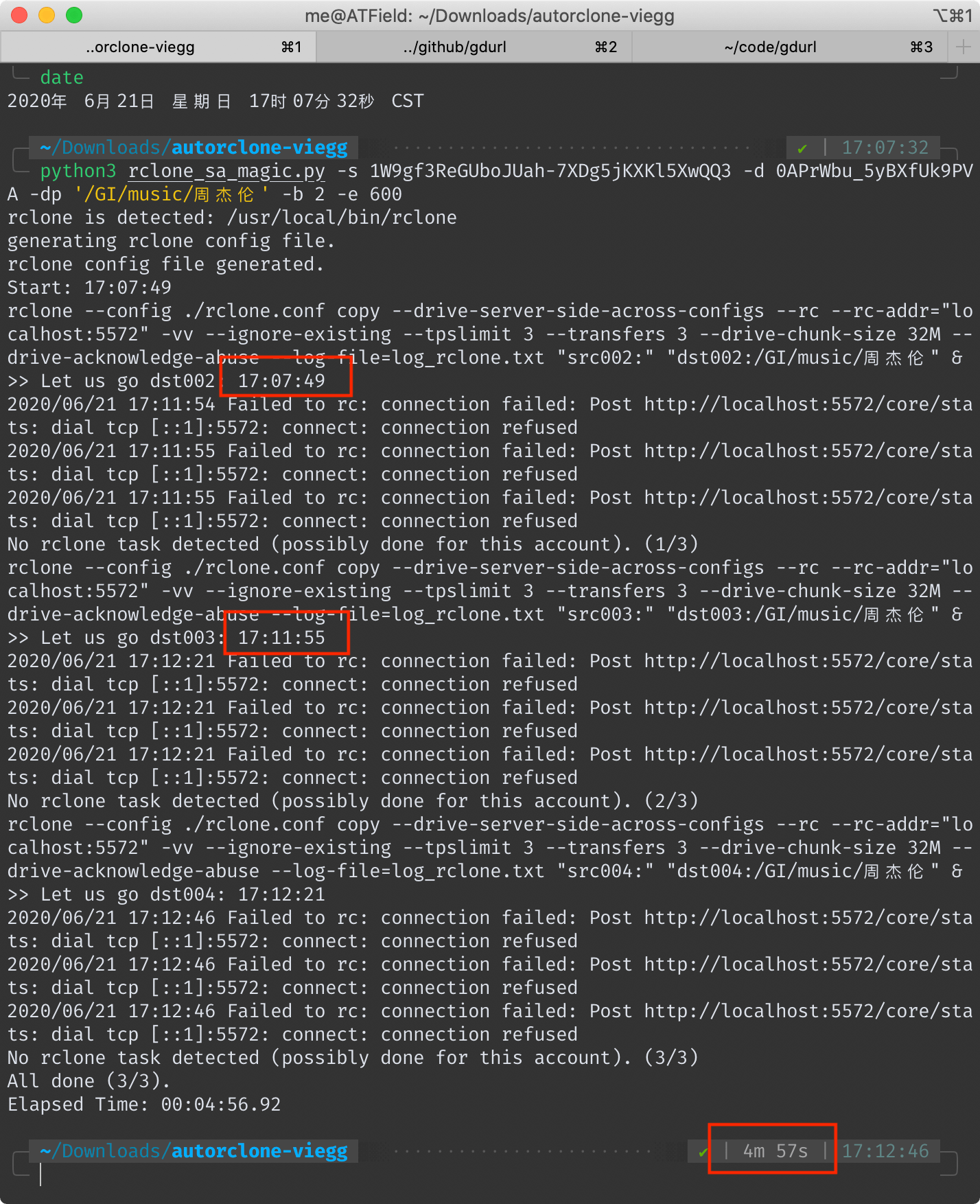 -->
|
||||

|
||||
|
||||
## gclone 耗时 3 分 7 秒
|
||||
<!-- 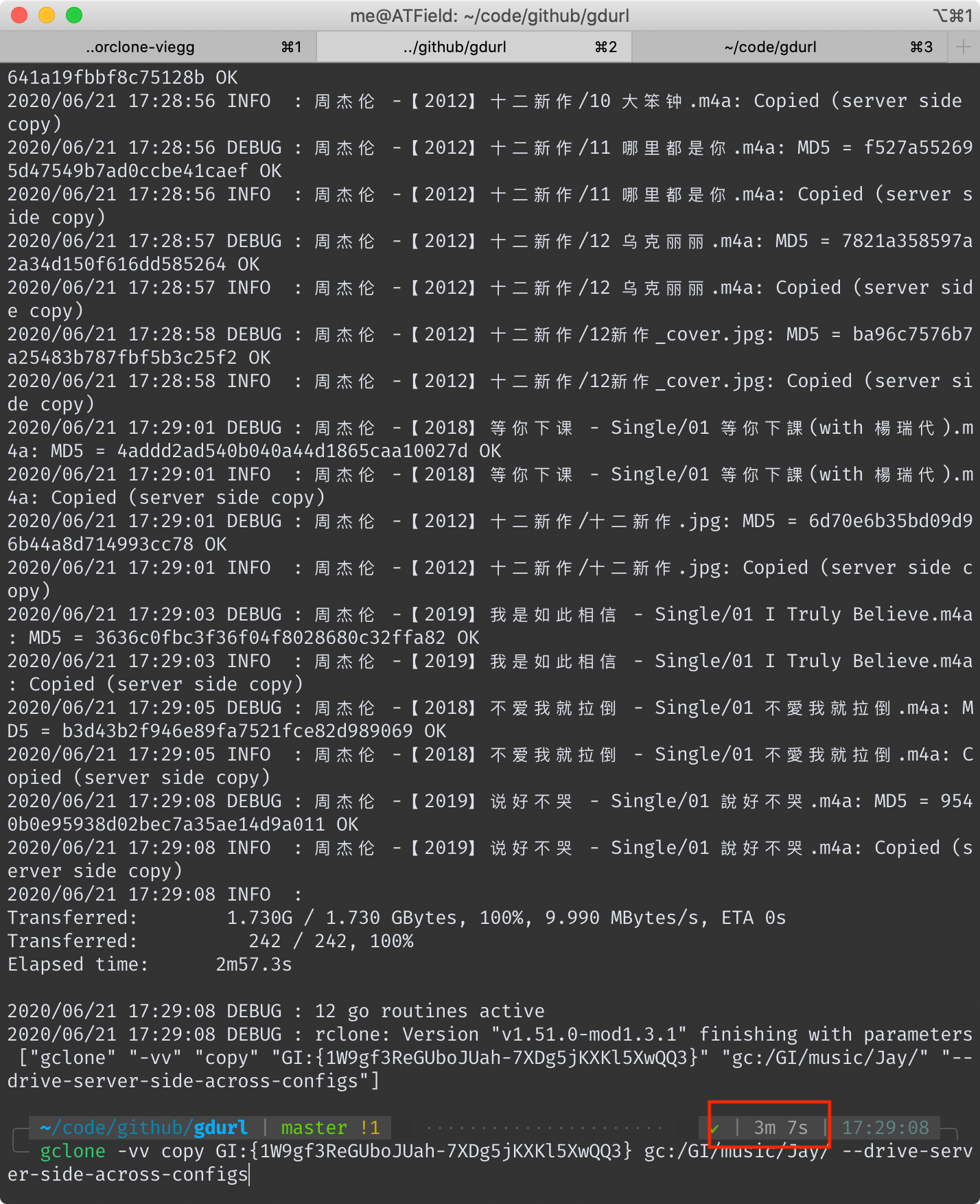 -->
|
||||

|
||||
|
||||
## 为什么速度会有这么大差异
|
||||
首先要明确一下 server side copy(后称ssc) 的原理。
|
||||
|
||||
对于 Google Drive 本身而言,它不会因为你ssc复制了一份文件而真的去在自己的文件系统上复制一遍(否则不管它有多大硬盘都会被填满),它只是在数据库里添上了一笔记录。
|
||||
|
||||
所以,无论ssc一份大文件还是小文件,理论上它的耗时都是一样的。
|
||||
各位在使用这些工具的时候也可以感受到,复制一堆小文件比复制几个大文件要慢得多。
|
||||
|
||||
Google Drive 官方的 API 只提供了复制单个文件的功能,无法直接复制整个文件夹。甚至也无法读取整个文件夹,只能读取某个文件夹的第一层子文件(夹)信息,类似 Linux 命令行里的 `ls` 命令。
|
||||
|
||||
这三个工具的ssc功能,本质上都是对[官方file copy api](https://developers.google.com/drive/api/v3/reference/files/copy)的调用。
|
||||
|
||||
然后说一下本工具的原理,其大概步骤如下:
|
||||
|
||||
- 首先,它会递归读取要复制的目录里的所有文件和文件夹的信息,并保存到本地。
|
||||
- 然后,将所有文件夹对象过滤出来,再根据彼此的父子关系,创建新的同名文件夹,还原出原始结构。(在保证速度的同时保持原始文件夹结构不变,这真的费了一番功夫)
|
||||
- 根据上一步创建文件夹时留下的新旧文件夹ID的对应关系,调用官方API复制文件。
|
||||
|
||||
得益于本地数据库的存在,它可以在任务中断后从断点继续执行。比如用户按下`ctrl+c`后,可以再执行一遍相同的拷贝命令,本工具会给出三个选项:
|
||||
<!--  -->
|
||||

|
||||
|
||||
另外两个工具也支持断点续传,它们是怎样做到的呢?AutoRclone是用python对rclone命令的一层封装,gclone是基于rclone的魔改。
|
||||
对了——值得一提的是——本工具是直接调用的官方API,不依赖于rclone。
|
||||
|
||||
我没有仔细阅读过rclone的源码,但是从它的执行日志中可以大概猜出其工作原理。
|
||||
先补充个背景知识:对于存在于Google drive的所有文件(夹)对象,它们的一生都伴随着一个独一无二的ID,就算一个文件是另一个的拷贝,它们的ID也不一样。
|
||||
|
||||
所以rclone是怎么知道哪些文件拷贝过,哪些没有呢?如果它没有像我一样将记录保存在本地数据库的话,那么它只能在同一路径下搜索是否存在同名文件,如果存在,再比对它们的 大小/修改时间/md5值 等判断是否拷贝过。
|
||||
|
||||
也就是说,在最坏的情况下(假设它没做缓存),它每拷贝一个文件之前,都要先调用官方API来搜索判断此文件是否已存在!
|
||||
|
||||
此外,AutoRclone和gclone虽然都支持自动切换service account,但是它们执行拷贝任务的时候都是单一SA在调用API,这就注定了它们不能把请求频率调太高——否则可能触发限制。
|
||||
|
||||
而本工具同样支持自动切换service account,区别在于它的每次请求都是随机选一个SA,我的[文件统计](https://gdurl.viegg.com/api/gdrive/count?fid=1W9gf3ReGUboJUah-7XDg5jKXKl5XwQQ3)接口就用了20个SA的token,同时请求数设置成20个,也就是平均而言,单个SA的并发请求数只有一次。
|
||||
|
||||
所以瓶颈不在于SA的频率限制,而在运行的vps或代理上,各位可以根据各自的情况适当调整 PARALLEL_LIMIT 的值(在 `config.js` 里)。
|
||||
|
||||
当然,如果某个SA的单日流量超过了750G,会自动切换成别的SA,同时过滤掉流量用尽的SA。当所有SA流量用完后,会切换到个人的access token,直到流量同样用尽,最终进程退出。
|
||||
|
||||
*使用SA存在的限制:除了每日流量限制外,其实每个SA还有个**15G的个人盘空间限额**,也就是说你每个SA最多能拷贝15G的文件到个人盘,但是拷贝到团队盘则无此限制。*
|
||||
# 對比本工具和其他類似工具在 server side copy 的速度上的差異
|
||||
### 這裡使用機器翻譯直接簡轉繁, 大家看得懂就好: )
|
||||
以拷貝[https://drive.google.com/drive/folders/1W9gf3ReGUboJUah-7XDg5jKXKl5XwQQ3](https://drive.google.com/drive/folders/1W9gf3ReGUboJUah-7XDg5jKXKl5XwQQ3)為例([文件統計](https://gdurl.viegg.com/api/gdrive/count?fid=1W9gf3ReGUboJUah-7XDg5jKXKl5XwQQ3))
|
||||
共 242 個文件和 26 個文件夾
|
||||
|
||||
如無特殊說明,以下運行環境都是在本地命令行(掛代理)
|
||||
|
||||
## 本工具耗時 40 秒
|
||||
<!--  -->
|
||||

|
||||
|
||||
另外我在一台洛杉磯的vps上執行相同的命令,耗時23秒。
|
||||
這個速度是在使用本項目默認配置**20個並行請求**得出來的,此值可自行修改(下文有方法),並行請求數越大,總速度越快。
|
||||
|
||||
## AutoRclone 耗時 4 分 57 秒(去掉拷貝後驗證時間 4 分 6 秒)
|
||||
<!--  -->
|
||||

|
||||
|
||||
## gclone 耗時 3 分 7 秒
|
||||
<!--  -->
|
||||

|
||||
|
||||
## 為什麽速度會有這麽大差異
|
||||
首先要明確一下 server side copy(後稱ssc) 的原理。
|
||||
|
||||
對於 Google Drive 本身而言,它不會因為你ssc覆制了一份文件而真的去在自己的文件系統上覆制一遍(否則不管它有多大硬盤都會被填滿),它只是在數據庫里添上了一筆記錄。
|
||||
|
||||
所以,無論ssc一份大文件還是小文件,理論上它的耗時都是一樣的。
|
||||
各位在使用這些工具的時候也可以感受到,覆制一堆小文件比覆制幾個大文件要慢得多。
|
||||
|
||||
Google Drive 官方的 API 只提供了覆制單個文件的功能,無法直接覆制整個文件夾。甚至也無法讀取整個文件夾,只能讀取某個文件夾的第一層子文件(夾)信息,類似 Linux 命令行里的 `ls` 命令。
|
||||
|
||||
這三個工具的ssc功能,本質上都是對[官方file copy api](https://developers.google.com/drive/api/v3/reference/files/copy)的調用。
|
||||
|
||||
然後說一下本工具的原理,其大概步驟如下:
|
||||
|
||||
- 首先,它會遞歸讀取要覆制的目錄里的所有文件和文件夾的信息,並保存到本地。
|
||||
- 然後,將所有文件夾對象過濾出來,再根據彼此的父子關系,創建新的同名文件夾,還原出原始結構。(在保證速度的同時保持原始文件夾結構不變,這真的費了一番功夫)
|
||||
- 根據上一步創建文件夾時留下的新舊文件夾ID的對應關系,調用官方API覆制文件。
|
||||
|
||||
得益於本地數據庫的存在,它可以在任務中斷後從斷點繼續執行。比如用戶按下`ctrl+c`後,可以再執行一遍相同的拷貝命令,本工具會給出三個選項:
|
||||
<!--  -->
|
||||

|
||||
|
||||
另外兩個工具也支持斷點續傳,它們是怎樣做到的呢?AutoRclone是用python對rclone命令的一層封裝,gclone是基於rclone的魔改。
|
||||
對了——值得一提的是——本工具是直接調用的官方API,不依賴於rclone。
|
||||
|
||||
我沒有仔細閱讀過rclone的源碼,但是從它的執行日志中可以大概猜出其工作原理。
|
||||
先補充個背景知識:對於存在於Google drive的所有文件(夾)對象,它們的一生都伴隨著一個獨一無二的ID,就算一個文件是另一個的拷貝,它們的ID也不一樣。
|
||||
|
||||
所以rclone是怎麽知道哪些文件拷貝過,哪些沒有呢?如果它沒有像我一樣將記錄保存在本地數據庫的話,那麽它只能在同一路徑下搜索是否存在同名文件,如果存在,再比對它們的 大小/修改時間/md5值 等判斷是否拷貝過。
|
||||
|
||||
也就是說,在最壞的情況下(假設它沒做緩存),它每拷貝一個文件之前,都要先調用官方API來搜索判斷此文件是否已存在!
|
||||
|
||||
此外,AutoRclone和gclone雖然都支持自動切換service account,但是它們執行拷貝任務的時候都是單一SA在調用API,這就注定了它們不能把請求頻率調太高——否則可能觸发限制。
|
||||
|
||||
而本工具同樣支持自動切換service account,區別在於它的每次請求都是隨機選一個SA,我的[文件統計](https://gdurl.viegg.com/api/gdrive/count?fid=1W9gf3ReGUboJUah-7XDg5jKXKl5XwQQ3)接口就用了20個SA的token,同時請求數設置成20個,也就是平均而言,單個SA的並发請求數只有一次。
|
||||
|
||||
所以瓶頸不在於SA的頻率限制,而在運行的vps或代理上,各位可以根據各自的情況適當調整 PARALLEL_LIMIT 的值(在 `config.js` 里)。
|
||||
|
||||
當然,如果某個SA的單日流量超過了750G,會自動切換成別的SA,同時過濾掉流量用盡的SA。當所有SA流量用完後,會切換到個人的access token,直到流量同樣用盡,最終進程退出。
|
||||
|
||||
*使用SA存在的限制:除了每日流量限制外,其實每個SA還有個**15G的個人盤空間限額**,也就是說你每個SA最多能拷貝15G的文件到個人盤,但是拷貝到團隊盤則無此限制。*
|
||||
|
||||
51
config.js
51
config.js
@ -1,24 +1,27 @@
|
||||
// 单次请求多少毫秒未响应以后超时(基准值,若连续超时则下次调整为上次的2倍)
|
||||
const TIMEOUT_BASE = 7000
|
||||
// 最大超时设置,比如某次请求,第一次7s超时,第二次14s,第三次28s,第四次56s,第五次不是112s而是60s,后续同理
|
||||
const TIMEOUT_MAX = 60000
|
||||
|
||||
const LOG_DELAY = 5000 // 日志输出时间间隔,单位毫秒
|
||||
const PAGE_SIZE = 1000 // 每次网络请求读取目录下的文件数,数值越大,越有可能超时,不得超过1000
|
||||
|
||||
const RETRY_LIMIT = 7 // 如果某次请求失败,允许其重试的最大次数
|
||||
const PARALLEL_LIMIT = 20 // 网络请求的并行数量,可根据网络环境调整
|
||||
|
||||
const DEFAULT_TARGET = '' // 必填,拷贝默认目的地ID,如果不指定target,则会复制到此处,建议填写团队盘ID
|
||||
|
||||
const AUTH = { // 如果您拥有service account的json授权文件,可将其拷贝至 sa 目录中以代替 client_id/secret/refrest_token
|
||||
client_id: 'your_client_id',
|
||||
client_secret: 'your_client_secret',
|
||||
refresh_token: 'your_refrest_token',
|
||||
expires: 0, // 可以留空
|
||||
access_token: '', // 可以留空
|
||||
tg_token: 'bot_token', // 你的 telegram robot 的 token,获取方法参见 https://core.telegram.org/bots#6-botfather
|
||||
tg_whitelist: ['your_tg_username'] // 你的tg username(t.me/username),bot只会执行这个列表里的用户所发送的指令
|
||||
}
|
||||
|
||||
module.exports = { AUTH, PARALLEL_LIMIT, RETRY_LIMIT, TIMEOUT_BASE, TIMEOUT_MAX, LOG_DELAY, PAGE_SIZE, DEFAULT_TARGET }
|
||||
// 单次请求多少毫秒未响应以后超时(基准值,若连续超时则下次调整为上次的2倍)
|
||||
const TIMEOUT_BASE = 7000
|
||||
// 最大超时设置,比如某次请求,第一次7s超时,第二次14s,第三次28s,第四次56s,第五次不是112s而是60s,后续同理
|
||||
const TIMEOUT_MAX = 60000
|
||||
|
||||
const LOG_DELAY = 5000 // 日志输出时间间隔,单位毫秒
|
||||
const PAGE_SIZE = 1000 // 每次网络请求读取目录下的文件数,数值越大,越有可能超时,不得超过1000
|
||||
|
||||
const RETRY_LIMIT = 7 // 如果某次请求失败,允许其重试的最大次数
|
||||
const PARALLEL_LIMIT = 20 // 网络请求的并行数量,可根据网络环境调整
|
||||
|
||||
const DEFAULT_TARGET = '' // 必填,拷贝默认目的地ID,如果不指定target,则会复制到此处,建议填写团队盘ID
|
||||
|
||||
const AUTH = { // 如果您拥有service account的json授权文件,可将其拷贝至 sa 目录中以代替 client_id/secret/refrest_token
|
||||
client_id: 'your_client_id',
|
||||
client_secret: 'your_client_secret',
|
||||
refresh_token: 'your_refrest_token',
|
||||
expires: 0, // 可以留空
|
||||
access_token: '', // 可以留空
|
||||
tg_token: 'bot_token', // 你的 telegram robot 的 token,获取方法参见 https://core.telegram.org/bots#6-botfather
|
||||
tg_whitelist: ['your_tg_username'] // 你的tg username(t.me/username),bot只会执行这个列表里的用户所发送的指令
|
||||
}
|
||||
|
||||
//-------------------MOD-------------------
|
||||
const SA_PATH = '../sa' //sa路徑配置, 給定絕對路徑或是以src為當前路徑給定相對路徑, 預設為'../sa'
|
||||
const BUTTON_LEVEL = 1 //預設為1, 填入大於2皆視為2
|
||||
module.exports = { AUTH, PARALLEL_LIMIT, RETRY_LIMIT, TIMEOUT_BASE, TIMEOUT_MAX, LOG_DELAY, PAGE_SIZE, DEFAULT_TARGET, SA_PATH, BUTTON_LEVEL }
|
||||
|
||||
8
copy
8
copy
@ -16,6 +16,8 @@ const { argv } = require('yargs')
|
||||
.describe('s', '不填默认拷贝全部文件,如果设置了这个值,则过滤掉小于这个size的文件,必须以b结尾,比如10mb')
|
||||
.alias('S', 'service_account')
|
||||
.describe('S', '指定使用service account进行操作,前提是必须在 ./sa 目录下放置json授权文件,请确保sa帐号拥有操作权限。')
|
||||
.alias('D', 'dncnr')
|
||||
.describe('D', 'do not create new root, 不在目的地创建同名文件夹,直接将源文件夹中的文件原样复制到目的文件夹中')
|
||||
.help('h')
|
||||
.alias('h', 'help')
|
||||
|
||||
@ -25,11 +27,11 @@ const { DEFAULT_TARGET } = require('./config')
|
||||
let [source, target] = argv._
|
||||
|
||||
if (validate_fid(source)) {
|
||||
const { name, update, file, not_teamdrive, size, service_account } = argv
|
||||
const { name, update, file, not_teamdrive, size, service_account, dncnr } = argv
|
||||
if (file) {
|
||||
target = target || DEFAULT_TARGET
|
||||
if (!validate_fid(target)) throw new Error('target id 格式不正确')
|
||||
return copy_file(source, target).then(r => {
|
||||
return copy_file(source, target, service_account).then(r => {
|
||||
const link = 'https://drive.google.com/drive/folders/' + target
|
||||
console.log('任务完成,文件所在位置:\n', link)
|
||||
}).catch(console.error)
|
||||
@ -39,7 +41,7 @@ if (validate_fid(source)) {
|
||||
console.log(`不复制大小低于 ${size} 的文件`)
|
||||
min_size = bytes.parse(size)
|
||||
}
|
||||
copy({ source, target, name, min_size, update, not_teamdrive, service_account }).then(folder => {
|
||||
copy({ source, target, name, min_size, update, not_teamdrive, service_account, dncnr }).then(folder => {
|
||||
if (!folder) return
|
||||
const link = 'https://drive.google.com/drive/folders/' + folder.id
|
||||
console.log('\n任务完成,新文件夹链接:\n', link)
|
||||
|
||||
@ -27,3 +27,19 @@ CREATE UNIQUE INDEX "task_source_target" ON "task" (
|
||||
"source",
|
||||
"target"
|
||||
);
|
||||
|
||||
CREATE TABLE "copied" (
|
||||
"taskid" INTEGER,
|
||||
"fileid" TEXT
|
||||
);
|
||||
|
||||
CREATE INDEX "copied_taskid" ON "copied" ("taskid");
|
||||
|
||||
CREATE TABLE "bookmark" (
|
||||
"alias" TEXT,
|
||||
"target" TEXT
|
||||
);
|
||||
|
||||
CREATE UNIQUE INDEX "bookmark_alias" ON "bookmark" (
|
||||
"alias"
|
||||
);
|
||||
|
||||
32
db.js
32
db.js
@ -2,4 +2,34 @@ const path = require('path')
|
||||
const db_location = path.join(__dirname, 'gdurl.sqlite')
|
||||
const db = require('better-sqlite3')(db_location)
|
||||
|
||||
module.exports = { db }
|
||||
db.pragma('journal_mode = WAL')
|
||||
|
||||
create_table_copied()
|
||||
function create_table_copied () {
|
||||
const [exists] = db.prepare('PRAGMA table_info(copied)').all()
|
||||
if (exists) return
|
||||
const create_table = `CREATE TABLE "copied" (
|
||||
"taskid" INTEGER,
|
||||
"fileid" TEXT
|
||||
)`
|
||||
db.prepare(create_table).run()
|
||||
const create_index = `CREATE INDEX "copied_taskid" ON "copied" ("taskid");`
|
||||
db.prepare(create_index).run()
|
||||
}
|
||||
|
||||
create_table_bookmark()
|
||||
function create_table_bookmark () {
|
||||
const [exists] = db.prepare('PRAGMA table_info(bookmark)').all()
|
||||
if (exists) return
|
||||
const create_table = `CREATE TABLE "bookmark" (
|
||||
"alias" TEXT,
|
||||
"target" TEXT
|
||||
);`
|
||||
db.prepare(create_table).run()
|
||||
const create_index = `CREATE UNIQUE INDEX "bookmark_alias" ON "bookmark" (
|
||||
"alias"
|
||||
);`
|
||||
db.prepare(create_index).run()
|
||||
}
|
||||
|
||||
module.exports = { db }
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 160 KiB |
@ -1,129 +0,0 @@
|
||||
# 几个坑
|
||||
* Telegram Bot API 提供了两种方式, webhook 和 long polling,目前项目只支持 webhook 方式。
|
||||
* webhook 方式必须要用HTTPS 也就是需要准备**个人域名**和**一个有效证书**
|
||||
* 证书一定要单独域名证书(泛域名证书不能用)
|
||||
|
||||
|
||||
|
||||
# 原理/思路
|
||||
TG创建bot,要起一个服务支持BOT的功能, 所以需要配置webhook 让tg 和服务器建立连接。webhook 需要有HTTPS的外网域名并且修改DNS指向你所配置的服务器IP,这样就能保证TG的请求可以顺利到达并且验证BOT。
|
||||
在服务器内部如果如果是单BOT, 可以直接用nodje 配合 PM2 直接起服务,然后修改server.js端口号443。 如果服务器上有多个服务,那么就需要用反向代理,反代简单说就是一个服务+映射规则 (ngnix或者apache后者其他都可以) 侦听80或者443端口,如果有指定的映射请求, 就转发到内部映射的各个服务。
|
||||
|
||||
例如
|
||||
```
|
||||
aaa.domain.com <=> locahost:3001
|
||||
bbb.domain.com <=> locahost:3002
|
||||
domain.com/ccc <=> localhost:3003
|
||||
```
|
||||
|
||||
|
||||
|
||||
# 步骤
|
||||
1. 需要去tg 创建一个bot,会得到token 和bot的tgurl
|
||||
2. BOT服务:
|
||||
1. 服务器上clone 项目,安装node, npm install
|
||||
2. 如果需要配置多个BOT, clone不同目录, server.js里修改配置port,和config.js
|
||||
3. 安装PM2,在每个bot目录下 PM2 start server.js
|
||||
4. ``` pm2 status``` 确认服务跑起来了
|
||||
1. 如果没起来, 查log文件(见底部)
|
||||
5. curl 检查本地连接, curl 检查远端连接, not found 就对了
|
||||
3. 外部连接
|
||||
1. 修改DNS,我是用cloudflare 把添加A record, 直接把静态IP 绑定
|
||||
2. 绑定以后, 本地开个terminal, ping 刚添加域名,直到解析的IP是你绑定的,这步确保连接上是畅通的
|
||||
4. apache2开启SSL和反代
|
||||
1. 复制证书到任意位置
|
||||
2. 运行底部命令
|
||||
3. /etc/apache2/sites-available 下找到默认的.conf,或者自己建个conf也行
|
||||
4. 修改底部配置信息
|
||||
5. 保存重启 ```service apache2 restart```
|
||||
5. 剩下的就是配置和检查webhook,这里面也有不少坑,在反代配置文件部分。。记不清了。。
|
||||
6. 如果一切顺利 /help 会弹出目录
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```
|
||||
pm2 部分
|
||||
|
||||
tail -200 ~/.pm2/logs/server-error.log
|
||||
tail -200 ~/.pm2/logs/server-out.log
|
||||
|
||||
curl "localhost:23333"
|
||||
curl "domain:23333"
|
||||
|
||||
SSL+反代
|
||||
|
||||
sudo a2enmod ssl
|
||||
sudo a2enmod proxy
|
||||
sudo a2enmod proxy_balancer
|
||||
sudo a2enmod proxy_http
|
||||
|
||||
|
||||
/etc/apache2/sites-available/xxx.conf
|
||||
|
||||
<VirtualHost *:443>
|
||||
SSLEngine on
|
||||
SSLProtocol all
|
||||
SSLCertificateFile {{CERT_DIR}}/{{domain.cer}}
|
||||
SSLCertificateKeyFile {{CERT_DIR}}/{{domain.key}}
|
||||
SSLCACertificateFile {{CERT_DIR}}/{{domain.ca.cer}}
|
||||
|
||||
ServerName {{domain}}
|
||||
|
||||
ProxyRequests Off
|
||||
ProxyPreserveHost On
|
||||
ProxyVia Full
|
||||
|
||||
<Proxy *>
|
||||
Require all granted
|
||||
</Proxy>
|
||||
# 这里我用的是子目录映射方式。懒得再申请一个证书。。domain.com/ccc <=> localhost:3003
|
||||
ProxyPass /{{bot1url}}/ http://127.0.0.1:23334/ # bot1
|
||||
ProxyPassReverse /{{bot1url}}/ http://127.0.0.1:23334/ # bot1
|
||||
ProxyPass /{{bot2url}}/ http://127.0.0.1:23333/ # bot2
|
||||
ProxyPassReverse /{{bot2url}}/ http://127.0.0.1:23333/ # bot2
|
||||
</VirtualHost>
|
||||
|
||||
|
||||
something for verify and DEBUG
|
||||
|
||||
Apache command:
|
||||
service apache2 restart
|
||||
service apache2 stop
|
||||
service apache2 status
|
||||
service apache2 reload
|
||||
tail -100 /var/log/apache2/error.log
|
||||
|
||||
|
||||
验证一下SSL:
|
||||
https://www.ssllabs.com/ssltest/analyze.html 确保Trusted和In trust store是绿的(反正我这两个绿的就TG就能找到的到)
|
||||
|
||||
SET webhook
|
||||
|
||||
curl -F "url=https://{{domain}}/{{bot1url}}/api/gdurl/tgbot" 'https://api.telegram.org/bot{{BOT_TOKEN}}/setWebhook'
|
||||
|
||||
delete webhook
|
||||
curl -F "url=" https://api.telegram.org/bot{{BOT_TOKEN}}/setWebhook
|
||||
|
||||
|
||||
check webhook
|
||||
curl "https://api.telegram.org/bot{{BOT_TOKEN}}/getWebhookInfo"
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
# Reference Link
|
||||
|
||||
https://core.telegram.org/bots
|
||||
|
||||
https://core.telegram.org/bots/api
|
||||
|
||||
https://www.jianshu.com/p/ca804497afa0
|
||||
@ -109,16 +109,16 @@ while [[ "${#YOUR_GOOGLE_TEAM_DRIVE_ID}" != 19 ]]; do
|
||||
done
|
||||
|
||||
cd ~ &&
|
||||
sed -i "s/bot_token/$YOUR_BOT_TOKEN/g" ./gd-utils/config.js &&
|
||||
sed -i "s/your_tg_username/$YOUR_TELEGRAM_ID/g" ./gd-utils/config.js &&
|
||||
sed -i "s/DEFAULT_TARGET = ''/DEFAULT_TARGET = '$YOUR_GOOGLE_TEAM_DRIVE_ID'/g" ./gd-utils/config.js
|
||||
sed -i "s/bot_token/$YOUR_BOT_TOKEN/g" ./gd-utils-cht/config.js &&
|
||||
sed -i "s/your_tg_username/$YOUR_TELEGRAM_ID/g" ./gd-utils-cht/config.js &&
|
||||
sed -i "s/DEFAULT_TARGET = ''/DEFAULT_TARGET = '$YOUR_GOOGLE_TEAM_DRIVE_ID'/g" ./gd-utils-cht/config.js
|
||||
echo -e "\033[1;32m----------------------------------------------------------\033[0m"
|
||||
|
||||
echo -e "\033[1;32m“进程守护程序pm2”开始安装......\033[0m"
|
||||
cd /root/gd-utils &&
|
||||
cd /root/gd-utils-cht &&
|
||||
npm i pm2 -g && pm2 l
|
||||
echo -e "\033[1;32m启动守护进程......\033[0m"
|
||||
pm2 start server.js
|
||||
pm2 start server.js --node-args="--max-old-space-size=4096"
|
||||
echo -e "\033[1;32m----------------------------------------------------------\033[0m"
|
||||
|
||||
echo -e "\033[1;32m“nginx”开始安装......\033[0m"
|
||||
@ -131,10 +131,18 @@ echo -e "\033[1;32m“nginx”起一个web服务......\033[0m"
|
||||
|
||||
cd $nginx_conf
|
||||
echo "server {
|
||||
listen 80;
|
||||
server_name $YOUR_DOMAIN_NAME;
|
||||
location / {
|
||||
proxy_pass http://127.0.0.1:23333/;
|
||||
listen 80;
|
||||
server_name $YOUR_DOMAIN_NAME;
|
||||
return 301 https://$host$request_uri;
|
||||
}
|
||||
server {
|
||||
listen 443 ssl;
|
||||
ssl on;
|
||||
ssl_certificate /etc/ssl/certificate.crt;
|
||||
ssl_certificate_key /etc/ssl/private.key;
|
||||
server_name $YOUR_DOMAIN_NAME;
|
||||
location / {
|
||||
proxy_pass http://127.0.0.1:23333/;
|
||||
}
|
||||
}" >${nginx_conf}gdutilsbot.conf &&
|
||||
$rm_nginx_default
|
||||
|
||||
@ -106,12 +106,12 @@ $cmd_install install $cmd_install_rely -y
|
||||
curl -sL $nodejs_curl | bash -
|
||||
$cmd_install install nodejs -y
|
||||
$cmd_install_rpm_build
|
||||
git clone https://github.com/iwestlin/gd-utils && cd gd-utils
|
||||
git clone https://github.com/liaojack8/gd-utils-cht && cd gd-utils-cht
|
||||
npm config set unsafe-perm=true
|
||||
npm i
|
||||
|
||||
echo
|
||||
echo -e "\033[1;32m★★★ 恭喜您!gdutils项目“TD查询转存”部分已部署完成,请上传sa到“./gd-utils/sa/”目录下完成最后的配置 ★★★\033[0m"
|
||||
echo -e "\033[1;32m★★★ 恭喜您!gdutils项目“TD查询转存”部分已部署完成,请上传sa到“./gd-utils-cht/sa/”目录下完成最后的配置 ★★★\033[0m"
|
||||
echo
|
||||
|
||||
cd ~
|
||||
|
||||
@ -117,12 +117,12 @@ $cmd_install install $cmd_install_rely -y
|
||||
curl -sL $nodejs_curl | bash -
|
||||
$cmd_install install nodejs -y
|
||||
$cmd_install_rpm_build
|
||||
git clone https://github.com/iwestlin/gd-utils && cd gd-utils
|
||||
git clone https://github.com/liaojack8/gd-utils-cht && cd gd-utils-cht
|
||||
npm config set unsafe-perm=true
|
||||
npm i
|
||||
|
||||
echo
|
||||
echo -e "\033[1;32m★★★ 恭喜您!gdutils统计转存系统已经正确安装完成,请上传sa到“./gd-utils/sa/”目录下完成最后的配置 ★★★\033[0m"
|
||||
echo -e "\033[1;32m★★★ 恭喜您!gdutils统计转存系统已经正确安装完成,请上传sa到“./gd-utils-cht/sa/”目录下完成最后的配置 ★★★\033[0m"
|
||||
echo
|
||||
|
||||
#################################################################################################
|
||||
@ -174,16 +174,16 @@ while [[ "${#YOUR_GOOGLE_TEAM_DRIVE_ID}" != 19 ]]; do
|
||||
done
|
||||
|
||||
cd ~ &&
|
||||
sed -i "s/bot_token/$YOUR_BOT_TOKEN/g" ./gd-utils/config.js &&
|
||||
sed -i "s/your_tg_username/$YOUR_TELEGRAM_ID/g" ./gd-utils/config.js &&
|
||||
sed -i "s/DEFAULT_TARGET = ''/DEFAULT_TARGET = '$YOUR_GOOGLE_TEAM_DRIVE_ID'/g" ./gd-utils/config.js
|
||||
sed -i "s/bot_token/$YOUR_BOT_TOKEN/g" ./gd-utils-cht/config.js &&
|
||||
sed -i "s/your_tg_username/$YOUR_TELEGRAM_ID/g" ./gd-utils-cht/config.js &&
|
||||
sed -i "s/DEFAULT_TARGET = ''/DEFAULT_TARGET = '$YOUR_GOOGLE_TEAM_DRIVE_ID'/g" ./gd-utils-cht/config.js
|
||||
echo -e "\033[1;32m----------------------------------------------------------\033[0m"
|
||||
|
||||
echo -e "\033[1;32m“进程守护程序pm2”开始安装......\033[0m"
|
||||
cd /root/gd-utils &&
|
||||
cd /root/gd-utils-cht &&
|
||||
npm i pm2 -g && pm2 l
|
||||
echo -e "\033[1;32m启动守护进程......\033[0m"
|
||||
pm2 start server.js
|
||||
pm2 start server.js --node-args="--max-old-space-size=4096"
|
||||
echo -e "\033[1;32m----------------------------------------------------------\033[0m"
|
||||
|
||||
echo -e "\033[1;32m“nginx”开始安装......\033[0m"
|
||||
@ -196,10 +196,18 @@ echo -e "\033[1;32m“nginx”起一个web服务......\033[0m"
|
||||
|
||||
cd $nginx_conf
|
||||
echo "server {
|
||||
listen 80;
|
||||
server_name $YOUR_DOMAIN_NAME;
|
||||
location / {
|
||||
proxy_pass http://127.0.0.1:23333/;
|
||||
listen 80;
|
||||
server_name $YOUR_DOMAIN_NAME;
|
||||
return 301 https://$host$request_uri;
|
||||
}
|
||||
server {
|
||||
listen 443 ssl;
|
||||
ssl on;
|
||||
ssl_certificate /etc/ssl/certificate.crt;
|
||||
ssl_certificate_key /etc/ssl/private.key;
|
||||
server_name $YOUR_DOMAIN_NAME;
|
||||
location / {
|
||||
proxy_pass http://127.0.0.1:23333/;
|
||||
}
|
||||
}" >${nginx_conf}gdutilsbot.conf &&
|
||||
$rm_nginx_default
|
||||
|
||||
BIN
pic/example2.png
Normal file
BIN
pic/example2.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 18 KiB |
BIN
pic/example3.png
Normal file
BIN
pic/example3.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 8.7 KiB |
293
readme.md
293
readme.md
@ -1,246 +1,155 @@
|
||||
# Google Drive 百宝箱
|
||||
# gd-utils-cht
|
||||
|
||||
> 不只是最快的 google drive 拷贝工具 [与其他工具的对比](./compare.md)
|
||||
> 不只是最快的 google drive 拷貝工具 [與其他工具的對比](./compare.md)
|
||||
|
||||
## 一键安装脚本
|
||||
- 安装机器人需准备好以下四个条件:
|
||||
- 在Telegram上注册好机器人并取得并记录下该机器人TOKEN
|
||||
- 一个域名在cloudflare解析到该机器人所在VPS的IP
|
||||
- 向机器人@userinfobot获取个人TG账号ID并记录
|
||||
- 注册好一个Google team drive加入sa并记录下该盘ID
|
||||
- 准备好以上四个条件后,复制以下全部内容粘贴到VPS命令行窗口回车即可
|
||||
- gdutils项目一键部署脚本(包括“查询转存”和“TG机器人”两部分)
|
||||
> 我的readme可能不夠完全, 主要寫上我更新、修改的內容, 具體說明還是看[這邊](https://github.com/iwestlin/gd-utils)和[這邊](https://github.com/vitaminx/gd-utils)吧
|
||||
## 更新紀錄
|
||||
### 2020.07.07
|
||||
- 參照原作者@iwestlin更新tg.js及gd.js
|
||||
- 整體繁體化, 介面部分
|
||||
- 新增用戶可以在config.js自訂按鈕顯示的個數(每列), 可設定為1或2
|
||||
### 2020.07.06
|
||||
- 部分繁體中文化
|
||||
- 執行/task命令時, 會回傳完成度百分比
|
||||
- 複製完成時, 跳出的通知會顯示文件大小
|
||||
## tg_bot 修改部分
|
||||
- 執行/task命令時, 會回傳完成度百分比
|
||||
|
||||

|
||||
- 複製完成時, 跳出的通知會顯示文件大小
|
||||
|
||||

|
||||
> 這邊說一下我用的服務及配置(免費配置): always-free gcp Compute Engine + zerossl + 免費的domain hosting
|
||||
>注意我的配置沒有用到cloudflare
|
||||
## 一鍵安裝腳本(感謝 腳本製作者 [@vitaminx](https://github.com/vitaminx))
|
||||
- 這邊的安裝腳本我有稍作修改 與fork過來的原版不一樣
|
||||
- 不使用cloudflare解析
|
||||
- ssl另外配置在nginx服務當中(後面會說明證書放置路徑)
|
||||
- 具體安裝條件、限制請去參考[腳本原作者的專案](https://github.com/vitaminx/gd-utils)
|
||||
- 這邊放了貼上就能用的命令
|
||||
- gdutils項目一鍵部署腳本(包括“查詢轉存”和“TG機器人”兩部分)
|
||||
```
|
||||
bash -c "$(curl -fsSL https://raw.githubusercontent.com/vitaminx/gd-utils/master/gdutilsinstall.sh)"
|
||||
bash -c "$(curl -fsSL https://raw.githubusercontent.com/liaojack8/gd-utils-cht/master/gdutilsinstall.sh)"
|
||||
```
|
||||
- gdutils项目一键部署脚本之“转存查询部分”
|
||||
- gdutils項目一鍵部署腳本之“轉存查詢部分”
|
||||
```
|
||||
bash -c "$(curl -fsSL https://raw.githubusercontent.com/vitaminx/gd-utils/master/gdutilscsinstall.sh)"
|
||||
bash -c "$(curl -fsSL https://raw.githubusercontent.com/liaojack8/gd-utils-cht/master/gdutilscsinstall.sh)"
|
||||
```
|
||||
- gdutils项目一键部署脚本之“TG机器人部分”
|
||||
- gdutils項目一鍵部署腳本之“TG機器人部分”
|
||||
```
|
||||
bash -c "$(curl -fsSL https://raw.githubusercontent.com/vitaminx/gd-utils/master/gdutilsbotinstall.sh)"
|
||||
bash -c "$(curl -fsSL https://raw.githubusercontent.com/liaojack8/gd-utils-cht/master/gdutilsbotinstall.sh)"
|
||||
```
|
||||
- 安装过程中需要输入一下四个参数:
|
||||
- 机器人TOKEN:这个在Telegram里面找“@BotFather”注册即可获得
|
||||
- Telegram用户ID:在Telegram里面向机器人@userinfobot发送消息即可获得
|
||||
- Google team drive ID:即为你转存文件的默认地址,脚本强制要求写谷歌团队盘ID
|
||||
- 安裝過程中需要輸入一下四個參數:
|
||||
- 機器人TOKEN:這個在Telegram裡面找“@BotFather”註冊即可獲得
|
||||
- Telegram用戶ID:在Telegram裡面向機器人@userinfobot发送消息即可獲得
|
||||
- Google team drive ID:即為你轉存文件的預設地址,腳本強制要求寫Google小組雲端硬碟ID
|
||||
- 域名:你在cloudflare上解析到VPS的域名(格式:abc.34513.com)
|
||||
- 脚本安装问题请信息发给TG:onekings 或 vitaminor@gmail.com
|
||||
- 系统使用问题(如无法转存、重启连不上机器人等等)请联系项目作者@vegg
|
||||
- 测试可用完美安装系统:
|
||||
- 腳本安裝問題請信息發給TG:onekings 或 vitaminor@gmail.com
|
||||
- 系統使用問題(如無法轉存、重啟連不上機器人等等)請聯系項目作者@vegg
|
||||
- 測試可用完美安裝系統:
|
||||
- Centos 7/8
|
||||
- debian 9/10
|
||||
- ubuntu 16.04/18.04/19.10/20.04
|
||||
|
||||
## demo
|
||||
[https://drive.google.com/drive/folders/124pjM5LggSuwI1n40bcD5tQ13wS0M6wg](https://drive.google.com/drive/folders/124pjM5LggSuwI1n40bcD5tQ13wS0M6wg)
|
||||
- ubuntu 16.04/18.04/19.10/20.04
|
||||
|
||||
## 更新日志
|
||||
[2020-06-30]
|
||||
## 搭建步驟
|
||||
1. 啟用一台主機, VPS、私人伺服器都行(私人伺服器如果沒有設定硬撥, 必須去路由器設定端口對應)
|
||||
2. 確認固定ip, 或是用ddns服務 都行
|
||||
3. 使用domain hosting服務解析到動態域名, 或新增A record指定到固定ip
|
||||
4. 用domain hosting設定好的固定域名, 去申請ssl證書
|
||||
5. 將證書放到對應路徑 /etc/ssl/certificate.crt 和 /etc/ssl/private.key
|
||||
6. 設定完成後, 確認主機的端口開放
|
||||
7. 執行安裝腳本, 就會自動以nginx起動服務, 特別設定了http轉https的跳轉
|
||||
|
||||
- 命令行操作时,不换行输出进度信息,同时将进度信息输出间隔调整为1秒
|
||||
- 隐藏 timeout exceed 报错信息
|
||||
|
||||
## 重要更新(2020-06-29)
|
||||
如果你遇到了以下几种问题,请务必阅读此节:
|
||||
|
||||
- 任务异常中断
|
||||
- 命令行日志无限循环输出但进度不变
|
||||
- 复制完发现丢文件
|
||||
|
||||
有不少网友遇到这些问题,但是作者一直无法复现,直到有tg网友发了张运行日志截图:
|
||||

|
||||
报错日志的意思是找不到对应的目录ID,这种情况会发生在SA没有对应目录的阅读权限的时候。
|
||||
当进行server side copy时,需要向Google的服务器提交要复制的文件ID,和复制的位置,也就是新创建的目录ID,由于在请求时是随机选取的SA,所以当选中没有权限的SA时,这次拷贝请求没有对应目录的权限,就会发生图中的错误。
|
||||
|
||||
**所以,上述这些问题的源头是,sa目录下,混杂了没有权限的json文件!**
|
||||
|
||||
以下是解决办法:
|
||||
- 在项目目录下,执行 `git pull` 拉取最新代码
|
||||
- 执行 `./validate-sa.js -h` 查看使用说明
|
||||
- 选择一个你的sa拥有阅读权限的目录ID,执行 `./validate-sa.js 你的目录ID`
|
||||
|
||||
程序会读取sa目录下所有json文件,依次检查它们是否拥有对 `你的目录ID` 的阅读权限,如果最后发现了无效的SA,程序会提供选项允许用户将无效的sa json移动到特定目录。
|
||||
|
||||
将无效sa文件移动以后,如果你使用了pm2启动,需要 `pm2 reload server` 重启下进程。
|
||||
|
||||
操作示例: [https://drive.google.com/drive/folders/1iiTAzWF_v9fo_IxrrMYiRGQ7QuPrnxHf](https://drive.google.com/drive/folders/1iiTAzWF_v9fo_IxrrMYiRGQ7QuPrnxHf)
|
||||
|
||||
## 常见问题
|
||||
下面是一些网友的踩坑心得,如果你配置的时候也不小心掉进坑里,可以进去找找有没有解决办法:
|
||||
|
||||
- [ikarosone 基于宝塔的搭建过程](https://www.ikarosone.top/archives/195.html)
|
||||
|
||||
- [@greathappyforest 踩的坑](doc/tgbot-appache2-note.md)
|
||||
|
||||
在命令行操作时如果输出 `timeout exceed` 这样的消息,是正常情况,不会影响最终结果,因为程序对每个请求都有7次重试的机制。
|
||||
如果timeout的消息比较多,可以考虑降低并行请求数,下文有具体方法。
|
||||
|
||||
复制结束后,如果最后输出的消息里有 `未读取完毕的目录ID`,只需要在命令行执行上次同样的拷贝命令,选continue即可继续。
|
||||
|
||||
如果你成功复制完以后,统计新的文件夹链接发现文件数比源文件夹少,说明Google正在更新数据库,请给它一点时间。。一般等半小时再统计数据会比较完整。
|
||||
|
||||
如果你使用tg操作时,发送拷贝命令以后,/task 进度始终未开始(在复制文件数超多的文件夹时常会发生),是正常现象。
|
||||
这是因为程序正在获取源文件夹的所有文件信息。它的运行机制严格按照以下顺序:
|
||||
|
||||
1、获取源文件夹所有文件信息
|
||||
2、根据源文件夹的目录结构,在目标文件夹创建目录
|
||||
3、所有目录创建完成后,开始复制文件
|
||||
|
||||
**如果源文件夹的文件数非常多(一百万以上),请一定在命令行进行操作**,因为程序运行的时候会把文件信息保存在内存中,文件数太多的话容易内存占用太多被nodejs干掉。可以像这样执行命令:
|
||||
```
|
||||
node --max-old-space-size=4096 count folder-id -S
|
||||
```
|
||||
这样进程就能最大占用4G内存了。
|
||||
|
||||
|
||||
## 搭建过程
|
||||
[https://drive.google.com/drive/folders/1Lu7Cwh9lIJkfqYDIaJrFpzi8Lgdxr4zT](https://drive.google.com/drive/folders/1Lu7Cwh9lIJkfqYDIaJrFpzi8Lgdxr4zT)
|
||||
|
||||
需要注意的地方:
|
||||
|
||||
- 视频中省略了一个比较重要的步骤就是**从本地上传service account授权文件到 sa 目录下**,tg机器人的所有操作都是通过sa授权的,所以你们别忘了。。
|
||||
- 视频中**nginx的配置里,server_name就是你的二级域名,需要和cloudflare的设置一样**的(mybbbottt),我分开录的视频所以没做到一致。
|
||||
- 还有省略的步骤就是注册域名和把域名托管到cloudflare了,这一步网上太多资料了,甚至也有免费注册(一年)域名的地方( https://www.freenom.com/ ),具体教程大家搜搜看吧。
|
||||
|
||||
## 功能简介
|
||||
## 功能簡介
|
||||
本工具目前支持以下功能:
|
||||
- 统计任意(您拥有相关权限的,下同,不再赘述)目录的文件信息,且支持以各种形式(html, table, json)导出。
|
||||
支持中断恢复,且统计过的目录(包括其所有子孙目录)信息会记录在本地数据库文件中(gdurl.sqlite)
|
||||
请在本项目目录下命令行输入 `./count -h` 查看使用帮助
|
||||
- 統計任意(您擁有相關權限的,下同,不再贅述)目錄的文件信息,且支持以各種形式(html, table, json)導出。
|
||||
支持中斷恢覆,且統計過的目錄(包括其所有子孫目錄)信息會記錄在本地數據庫文件中(gdurl.sqlite)
|
||||
請在本項目目錄下命令行輸入 `./count -h` 查看使用幫助
|
||||
|
||||
- 拷贝任意目录所有文件到您指定目录,同样支持中断恢复。
|
||||
支持根据文件大小过滤,可输入 `./copy -h` 查看使用帮助
|
||||
- 拷貝任意目錄所有文件到您指定目錄,同樣支持中斷恢覆。
|
||||
支持根據文件大小過濾,可輸入 `./copy -h` 查看使用幫助
|
||||
|
||||
- 对任意目录进行去重,删除同一目录下的md5值相同的文件(只保留一个),删除空目录。
|
||||
命令行输入 `./dedupe -h` 查看使用帮助
|
||||
- 對任意目錄進行去重,刪除同一目錄下的md5值相同的文件(只保留一個),刪除空目錄。
|
||||
命令行輸入 `./dedupe -h` 查看使用幫助
|
||||
|
||||
- 在 config.js 里完成相关配置后,可以将本项目部署在(可正常访问谷歌服务的)服务器上,提供 http api 文件统计接口
|
||||
- 在 config.js 里完成相關配置後,可以將本項目部署在(可正常訪問Google服務的)服務器上,提供 http api 文件統計接口
|
||||
|
||||
- 支持 telegram bot,配置完成后,上述功能均可通过 bot 进行操作
|
||||
- 支持 telegram bot,配置完成後,上述功能均可通過 bot 進行操作
|
||||
|
||||
## 环境配置
|
||||
本工具需要安装nodejs,客户端安装请访问[https://nodejs.org/zh-cn/download/](https://nodejs.org/zh-cn/download/),服务器安装可参考[https://github.com/nodesource/distributions/blob/master/README.md#debinstall](https://github.com/nodesource/distributions/blob/master/README.md#debinstall)
|
||||
## 環境配置
|
||||
本工具需要安裝nodejs,客戶端安裝請訪問[https://nodejs.org/zh-cn/download/](https://nodejs.org/zh-cn/download/),服務器安裝可參考[https://github.com/nodesource/distributions/blob/master/README.md#debinstall](https://github.com/nodesource/distributions/blob/master/README.md#debinstall)
|
||||
|
||||
建议选择v12版本的node,以防接下来安装依赖出错。
|
||||
建議選擇v12版本的node,以防接下來安裝依賴出錯。
|
||||
|
||||
如果你的网络环境无法正常访问谷歌服务,需要先在命令行进行一些配置:(如果可以正常访问则跳过此节)
|
||||
如果你的網絡環境無法正常訪問Google服務,需要先在命令行進行一些配置:(如果可以正常訪問則跳過此節)
|
||||
```
|
||||
http_proxy="YOUR_PROXY_URL" && https_proxy=$http_proxy && HTTP_PROXY=$http_proxy && HTTPS_PROXY=$http_proxy
|
||||
```
|
||||
请把`YOUR_PROXY_URL`替换成你自己的代理地址
|
||||
請把`YOUR_PROXY_URL`替換成你自己的代理地址
|
||||
|
||||
## 依赖安装
|
||||
- 命令行执行`git clone https://github.com/iwestlin/gd-utils && cd gd-utils` 克隆并切换到本项目文件夹下
|
||||
- **执行 `npm install --unsafe-perm=true --allow-root` 安装依赖**,部分依赖可能需要代理环境才能下载,所以需要上一步的配置
|
||||
## 依賴安裝
|
||||
- 命令行執行`git clone https://github.com/iwestlin/gd-utils && cd gd-utils` 克隆並切換到本項目文件夾下
|
||||
- **執行 `npm install --unsafe-perm=true --allow-root` 安裝依賴**,部分依賴可能需要代理環境才能下載,所以需要上一步的配置
|
||||
|
||||
如果在安装过程中发生报错,请切换nodejs版本到v12再试。如果报错信息里有`Error: not found: make`之类的消息,说明你的命令行环境缺少make命令,可参考[这里](https://askubuntu.com/questions/192645/make-command-not-found)或直接google搜索`Make Command Not Found`
|
||||
如果在安裝過程中发生報錯,請切換nodejs版本到v12再試。如果報錯信息里有`Error: not found: make`之類的消息,說明你的命令行環境缺少make命令,可參考[這里](https://askubuntu.com/questions/192645/make-command-not-found)或直接google搜索`Make Command Not Found`
|
||||
|
||||
如果报错信息里有 `better-sqlite3`,先执行 `npm config set unsafe-perm=true`
|
||||
然后 `rm -rf node_module` 删掉依赖目录,最后再执行下`npm i`安装试试。
|
||||
如果報錯信息里有 `better-sqlite3`,先執行 `npm config set unsafe-perm=true`
|
||||
然後 `rm -rf node_module` 刪掉依賴目錄,最後再執行下`npm i`安裝試試。
|
||||
|
||||
依赖安装完成后,项目文件夹下会多出个`node_modules`目录,请不要删除它,接下来进行下一步配置。
|
||||
依賴安裝完成後,項目文件夾下會多出個`node_modules`目錄,請不要刪除它,接下來進行下一步配置。
|
||||
|
||||
## Service Account 配置
|
||||
强烈建议使用service account(后称SA), 获取方法请参见 [https://gsuitems.com/index.php/archives/13/](https://gsuitems.com/index.php/archives/13/#%E6%AD%A5%E9%AA%A42%E7%94%9F%E6%88%90serviceaccounts)
|
||||
获取到 SA 的 json 文件后,请将其拷贝到 `sa` 目录下
|
||||
強烈建議使用service account(後稱SA), 獲取方法請參見 [https://gsuitems.com/index.php/archives/13/](https://gsuitems.com/index.php/archives/13/#%E6%AD%A5%E9%AA%A42%E7%94%9F%E6%88%90serviceaccounts)
|
||||
獲取到 SA 的 json 文件後,請將其拷貝到 `sa` 目錄下
|
||||
|
||||
配置好 SA 以后,如果你不需要对个人盘下的文件进行操作,可跳过[个人帐号配置]这节,而且执行命令的时候,记得带上 `-S` 参数告诉程序使用SA授权进行操作。
|
||||
配置好 SA 以後,如果你不需要對個人盤下的文件進行操作,可跳過[個人帳號配置]這節,而且執行命令的時候,記得帶上 `-S` 參數告訴程序使用SA授權進行操作。
|
||||
|
||||
## 个人帐号配置
|
||||
- 命令行执行 `rclone config file` 找到 rclone 的配置文件路径
|
||||
- 打开这个配置文件 `rclone.conf`, 找到 `client_id`, `client_secret` 和 `refresh_token` 这三个变量,将其分别填入本项目下的 `config.js` 中,需要注意这三个值必须被成对的英文引号包裹,且引号后以英文逗号结尾,也就是需要符合JavaScript的[对象语法](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operators/Object_initializer)
|
||||
## 個人帳號配置
|
||||
- 命令行執行 `rclone config file` 找到 rclone 的配置文件路徑
|
||||
- 打開這個配置文件 `rclone.conf`, 找到 `client_id`, `client_secret` 和 `refresh_token` 這三個變量,將其分別填入本項目下的 `config.js` 中,需要注意這三個值必須被成對的英文引號包裹,且引號後以英文逗號結尾,也就是需要符合JavaScript的[對象語法](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operators/Object_initializer)
|
||||
|
||||
如果你没有配置过rclone,可以搜索`rclone google drive 教程`完成相关配置。
|
||||
如果你沒有配置過rclone,可以搜索`rclone google drive 教程`完成相關配置。
|
||||
|
||||
如果你的`rclone.conf`里没有`client_id`和`client_secret`,说明你配置rclone的时候默认用了rclone自己的client_id,连rclone自己[都不建议这样做](https://github.com/rclone/rclone/blob/8d55367a6a2f47a1be7e360a872bd7e56f4353df/docs/content/drive.md#making-your-own-client_id),因为大家共享了它的接口调用限额,在使用高峰期可能会触发限制。
|
||||
如果你的`rclone.conf`里沒有`client_id`和`client_secret`,說明你配置rclone的時候默認用了rclone自己的client_id,連rclone自己[都不建議這樣做](https://github.com/rclone/rclone/blob/8d55367a6a2f47a1be7e360a872bd7e56f4353df/docs/content/drive.md#making-your-own-client_id),因為大家共享了它的接口調用限額,在使用高峰期可能會觸发限制。
|
||||
|
||||
获取自己的clinet_id可以参见这两篇文章:[Cloudbox/wiki/Google-Drive-API-Client-ID-and-Client-Secret](https://github.com/Cloudbox/Cloudbox/wiki/Google-Drive-API-Client-ID-and-Client-Secret) 和 [https://p3terx.com/archives/goindex-google-drive-directory-index.html#toc_2](https://p3terx.com/archives/goindex-google-drive-directory-index.html#toc_2)
|
||||
獲取自己的clinet_id可以參見這兩篇文章:[Cloudbox/wiki/Google-Drive-API-Client-ID-and-Client-Secret](https://github.com/Cloudbox/Cloudbox/wiki/Google-Drive-API-Client-ID-and-Client-Secret) 和 [https://p3terx.com/archives/goindex-google-drive-directory-index.html#toc_2](https://p3terx.com/archives/goindex-google-drive-directory-index.html#toc_2)
|
||||
|
||||
获取到client_id和client_secret后,再次执行一遍`rclone config`,创建一个新的remote,**在配置过程中一定要填入你新获取的clinet_id和client_secret**,就能在`rclone.conf`里看到新获取的`refresh_token`了。**注意,不能使用之前的refrest_token**,因为它对应的是rclone自带的client_id
|
||||
獲取到client_id和client_secret後,再次執行一遍`rclone config`,創建一個新的remote,**在配置過程中一定要填入你新獲取的clinet_id和client_secret**,就能在`rclone.conf`里看到新獲取的`refresh_token`了。**注意,不能使用之前的refrest_token**,因為它對應的是rclone自帶的client_id
|
||||
|
||||
参数配置好以后,在命令行执行 `node check.js`,如果命令返回了你的谷歌硬盘根目录的数据,说明配置成功,可以开始使用本工具了。
|
||||
參數配置好以後,在命令行執行 `node check.js`,如果命令返回了你的Google雲端硬碟根目錄的數據,說明配置成功,可以開始使用本工具了。
|
||||
|
||||
## Bot配置
|
||||
如果要使用 telegram bot 功能,需要进一步配置。
|
||||
如果要使用 telegram bot 功能,需要進一步配置。
|
||||
|
||||
首先在 [https://core.telegram.org/bots#6-botfather](https://core.telegram.org/bots#6-botfather) 根据指示拿到 bot 的 token,然后填入 config.js 中的 `tg_token` 变量。
|
||||
首先在 [https://core.telegram.org/bots#6-botfather](https://core.telegram.org/bots#6-botfather) 根據指示拿到 bot 的 token,然後填入 config.js 中的 `tg_token` 變量。
|
||||
|
||||
然后获取自己的 telegram username,这个username不是显示的名称,而是tg个人网址后面的那串字符,比如,我的tg个人网址是 `https://t.me/viegg` ,用户名就是 `viegg`,获取用户名的目的是在代码里配置白名单,只允许特定的用户调用机器人。将username填入 `config.js`里的配置,像这样:
|
||||
`tg_whitelist: ['viegg']`,就代表只允许我自己使用这个机器人了。
|
||||
然後獲取自己的 telegram username,這個username不是顯示的名稱,而是tg個人網址後面的那串字符,比如,我的tg個人網址是 `https://t.me/viegg` ,用戶名就是 `viegg`,獲取用戶名的目的是在代碼里配置白名單,只允許特定的用戶調用機器人。將username填入 `config.js`里的配置,像這樣:
|
||||
`tg_whitelist: ['viegg']`,就代表只允許我自己使用這個機器人了。
|
||||
|
||||
如果想把机器人的使用权限分享给别的用户,只需要改成这样子: `tg_whitelist: ['viegg', '其他人的username']`
|
||||
如果想把機器人的使用權限分享給別的用戶,只需要改成這樣子: `tg_whitelist: ['viegg', '其他人的username']`
|
||||
|
||||
接下来需要将代码部署到服务器上。
|
||||
如果你一开始就是在服务器上配置的,可以直接执行`npm i pm2 -g`
|
||||
|
||||
如果你之前是在本地操作的,请在服务器上同样重复一遍,配置好相关参数后,执行`npm i pm2 -g`安装进程守护程序pm2
|
||||
|
||||
安装好pm2之后,执行 `pm2 start server.js`,代码运行后会在服务器上监听`23333`端口。
|
||||
|
||||
如果你启动程序后想看运行日志,执行 `pm2 logs`
|
||||
|
||||
查看 pm2 守护的进程列表,执行 `pm2 l`
|
||||
|
||||
停止运行中的进程,执行 `pm2 stop 对应的进程名称`
|
||||
|
||||
**如果你修改了代码中的配置,需要 `pm2 reload server` 才能生效**。
|
||||
|
||||
> 如果你不想用nginx,可以将`server.js`中的`23333`改成`80`直接监听80端口(可能需要root权限)
|
||||
|
||||
接下来可通过nginx或其他工具起一个web服务,示例nginx配置:
|
||||
## 補充說明
|
||||
在`config.js`文件里,還有另外的幾個參數:
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
server_name your.server.name;
|
||||
|
||||
location / {
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_pass http://127.0.0.1:23333/;
|
||||
}
|
||||
}
|
||||
```
|
||||
配置好nginx后,可以再套一层cloudflare,具体教程请自行搜索。
|
||||
|
||||
检查网站是否部署成功,可以命令行执行(请将YOUR_WEBSITE_URL替换成你的网址)
|
||||
```
|
||||
curl 'YOUR_WEBSITE_URL/api/gdurl/count?fid=124pjM5LggSuwI1n40bcD5tQ13wS0M6wg'
|
||||
```
|
||||

|
||||
|
||||
如果返回了这样的文件统计,说明部署成功了。
|
||||
|
||||
最后,在命令行执行(请将[YOUR_WEBSITE]和[YOUR_BOT_TOKEN]分别替换成你自己的网址和bot token)
|
||||
```
|
||||
curl -F "url=[YOUR_WEBSITE]/api/gdurl/tgbot" 'https://api.telegram.org/bot[YOUR_BOT_TOKEN]/setWebhook'
|
||||
```
|
||||
这样,就将你的服务器连接上你的 telegram bot 了,试着给bot发送个 `/help`,如果它回复给你使用说明,那就配置成功了。
|
||||
|
||||
## 补充说明
|
||||
在`config.js`文件里,还有另外的几个参数:
|
||||
```
|
||||
// 单次请求多少毫秒未响应以后超时(基准值,若连续超时则下次调整为上次的2倍)
|
||||
// 單次請求多少毫秒未響應以後超時(基準值,若連續超時則下次調整為上次的2倍)
|
||||
const TIMEOUT_BASE = 7000
|
||||
|
||||
// 最大超时设置,比如某次请求,第一次7s超时,第二次14s,第三次28s,第四次56s,第五次不是112s而是60s,后续同理
|
||||
// 最大超時設置,比如某次請求,第一次7s超時,第二次14s,第三次28s,第四次56s,第五次不是112s而是60s,後續同理
|
||||
const TIMEOUT_MAX = 60000
|
||||
|
||||
const LOG_DELAY = 5000 // 日志输出时间间隔,单位毫秒
|
||||
const PAGE_SIZE = 1000 // 每次网络请求读取目录下的文件数,数值越大,越有可能超时,不得超过1000
|
||||
const LOG_DELAY = 5000 // 日志輸出時間間隔,單位毫秒
|
||||
const PAGE_SIZE = 1000 // 每次網絡請求讀取目錄下的文件數,數值越大,越有可能超時,不得超過1000
|
||||
|
||||
const RETRY_LIMIT = 7 // 如果某次请求失败,允许其重试的最大次数
|
||||
const PARALLEL_LIMIT = 20 // 网络请求的并行数量,可根据网络环境调整
|
||||
const RETRY_LIMIT = 7 // 如果某次請求失敗,允許其重試的最大次數
|
||||
const PARALLEL_LIMIT = 20 // 網絡請求的並行數量,可根據網絡環境調整
|
||||
|
||||
const DEFAULT_TARGET = '' // 必填,拷贝默认目的地ID,如果不指定target,则会拷贝到此处,建议填写团队盘ID,注意要用英文引号包裹
|
||||
const DEFAULT_TARGET = '' // 必填,拷貝默認目的地ID,如果不指定target,則會拷貝到此處,建議填寫團隊盤ID,注意要用英文引號包裹
|
||||
```
|
||||
读者可根据各自情况进行调整
|
||||
讀者可根據各自情況進行調整
|
||||
|
||||
## 注意事项
|
||||
程序的原理是调用了[google drive官方接口](https://developers.google.com/drive/api/v3/reference/files/list),递归获取目标文件夹下所有文件及其子文件夹信息,粗略来讲,某个目录下包含多少个文件夹,就至少需要这么多次请求才能统计完成。
|
||||
## 注意事項
|
||||
程序的原理是調用了[google drive官方接口](https://developers.google.com/drive/api/v3/reference/files/list),遞歸獲取目標文件夾下所有文件及其子文件夾信息,粗略來講,某個目錄下包含多少個文件夾,就至少需要這麽多次請求才能統計完成。
|
||||
|
||||
目前尚不知道google是否会对接口做频率限制,也不知道会不会影响google账号本身的安全。
|
||||
目前尚不知道google是否會對接口做頻率限制,也不知道會不會影響google賬號本身的安全。
|
||||
|
||||
**请勿滥用,后果自负**
|
||||
**請勿濫用,後果自負**
|
||||
|
||||
271
src/gd.js
271
src/gd.js
@ -8,23 +8,37 @@ const HttpsProxyAgent = require('https-proxy-agent')
|
||||
const { GoogleToken } = require('gtoken')
|
||||
const handle_exit = require('signal-exit')
|
||||
|
||||
const { AUTH, RETRY_LIMIT, PARALLEL_LIMIT, TIMEOUT_BASE, TIMEOUT_MAX, LOG_DELAY, PAGE_SIZE, DEFAULT_TARGET } = require('../config')
|
||||
const { AUTH, RETRY_LIMIT, PARALLEL_LIMIT, TIMEOUT_BASE, TIMEOUT_MAX, LOG_DELAY, PAGE_SIZE, DEFAULT_TARGET, SA_PATH } = require('../config')
|
||||
const { db } = require('../db')
|
||||
const { make_table, make_tg_table, make_html, summary } = require('./summary')
|
||||
|
||||
const FILE_EXCEED_MSG = '您的小組雲端硬碟文件數量已超過限制(40萬),停止複製'
|
||||
const FOLDER_TYPE = 'application/vnd.google-apps.folder'
|
||||
const { https_proxy } = process.env
|
||||
const axins = axios.create(https_proxy ? { httpsAgent: new HttpsProxyAgent(https_proxy) } : {})
|
||||
|
||||
const SA_FILES = fs.readdirSync(path.join(__dirname, '../sa')).filter(v => v.endsWith('.json'))
|
||||
const SA_BATCH_SIZE = 1000
|
||||
const SA_FILES = fs.readdirSync(path.join(__dirname, SA_PATH)).filter(v => v.endsWith('.json'))
|
||||
SA_FILES.flag = 0
|
||||
let SA_TOKENS = get_sa_batch()
|
||||
|
||||
let SA_TOKENS = SA_FILES.map(filename => {
|
||||
const gtoken = new GoogleToken({
|
||||
keyFile: path.join(__dirname, '../sa', filename),
|
||||
scope: ['https://www.googleapis.com/auth/drive']
|
||||
setInterval(() => {
|
||||
SA_FILES.flag = 0
|
||||
SA_TOKENS = get_sa_batch()
|
||||
}, 1000 * 3600 * 12)
|
||||
|
||||
function get_sa_batch () {
|
||||
const new_flag = SA_FILES.flag + SA_BATCH_SIZE
|
||||
const files = SA_FILES.slice(SA_FILES.flag, new_flag)
|
||||
SA_FILES.flag = new_flag
|
||||
return files.map(filename => {
|
||||
const gtoken = new GoogleToken({
|
||||
keyFile: path.join(__dirname, '../sa', filename),
|
||||
scope: ['https://www.googleapis.com/auth/drive']
|
||||
})
|
||||
return { gtoken, expires: 0 }
|
||||
})
|
||||
return { gtoken, expires: 0 }
|
||||
})
|
||||
}
|
||||
|
||||
handle_exit(() => {
|
||||
// console.log('handle_exit running')
|
||||
@ -38,11 +52,13 @@ handle_exit(() => {
|
||||
async function gen_count_body ({ fid, type, update, service_account }) {
|
||||
async function update_info () {
|
||||
const info = await walk_and_save({ fid, update, service_account }) // 这一步已经将fid记录存入数据库中了
|
||||
const { summary } = db.prepare('SELECT summary from gd WHERE fid=?').get(fid)
|
||||
return [info, JSON.parse(summary)]
|
||||
const row = db.prepare('SELECT summary from gd WHERE fid=?').get(fid)
|
||||
if (!row) return []
|
||||
return [info, JSON.parse(row.summary)]
|
||||
}
|
||||
|
||||
function render_smy (smy, type) {
|
||||
if (!smy) return
|
||||
if (['html', 'curl', 'tg'].includes(type)) {
|
||||
smy = (typeof smy === 'object') ? smy : JSON.parse(smy)
|
||||
const type_func = {
|
||||
@ -66,7 +82,7 @@ async function gen_count_body ({ fid, type, update, service_account }) {
|
||||
if (!info) { // 说明上次统计过程中断了
|
||||
[info] = await update_info()
|
||||
}
|
||||
return JSON.stringify(info)
|
||||
return info && JSON.stringify(info)
|
||||
}
|
||||
if (smy) return render_smy(smy, type)
|
||||
if (record && record.summary) return render_smy(record.summary, type)
|
||||
@ -86,7 +102,7 @@ async function count ({ fid, update, sort, type, output, not_teamdrive, service_
|
||||
if (!update) {
|
||||
const info = get_all_by_fid(fid)
|
||||
if (info) {
|
||||
console.log('找到本地缓存数据,缓存时间:', dayjs(info.mtime).format('YYYY-MM-DD HH:mm:ss'))
|
||||
console.log('找到本地快取資料,快取時間:', dayjs(info.mtime).format('YYYY-MM-DD HH:mm:ss'))
|
||||
const out_str = get_out_str({ info, type, sort })
|
||||
if (output) return fs.writeFileSync(output, out_str)
|
||||
return console.log(out_str)
|
||||
@ -154,7 +170,7 @@ async function walk_and_save ({ fid, not_teamdrive, update, service_account }) {
|
||||
|
||||
const loop = setInterval(() => {
|
||||
const now = dayjs().format('HH:mm:ss')
|
||||
const message = `${now} | 已获取对象 ${result.length} | 排队等候的网络请求 ${limit.pendingCount}`
|
||||
const message = `${now} | 已獲取對象 ${result.length} | 網路請求 進行中${limit.activeCount}/排隊中${limit.pendingCount}`
|
||||
print_progress(message)
|
||||
}, 1000)
|
||||
|
||||
@ -185,8 +201,8 @@ async function walk_and_save ({ fid, not_teamdrive, update, service_account }) {
|
||||
} catch (e) {
|
||||
console.error(e)
|
||||
}
|
||||
console.log('\n信息获取完毕')
|
||||
not_finished.length ? console.log('未读取完毕的目录ID:', JSON.stringify(not_finished)) : console.log('所有目录读取完毕')
|
||||
console.log('\n資訊獲取完畢')
|
||||
not_finished.length ? console.log('未讀取完畢的目錄ID:', JSON.stringify(not_finished)) : console.log('所有目錄讀取完畢')
|
||||
clearInterval(loop)
|
||||
const smy = summary(result)
|
||||
db.prepare('UPDATE gd SET summary=?, mtime=? WHERE fid=?').run(JSON.stringify(smy), Date.now(), fid)
|
||||
@ -217,7 +233,8 @@ async function ls_folder ({ fid, not_teamdrive, service_account }) {
|
||||
params.orderBy = 'folder,name desc'
|
||||
params.fields = 'nextPageToken, files(id, name, mimeType, size, md5Checksum)'
|
||||
params.pageSize = Math.min(PAGE_SIZE, 1000)
|
||||
const use_sa = (fid !== 'root') && (service_account || !not_teamdrive) // 不带参数默认使用sa
|
||||
// const use_sa = (fid !== 'root') && (service_account || !not_teamdrive) // 不带参数默认使用sa
|
||||
const use_sa = (fid !== 'root') && service_account
|
||||
const headers = await gen_headers(use_sa)
|
||||
do {
|
||||
if (pageToken) params.pageToken = pageToken
|
||||
@ -236,7 +253,7 @@ async function ls_folder ({ fid, not_teamdrive, service_account }) {
|
||||
}
|
||||
}
|
||||
if (!data) {
|
||||
console.error('读取目录未完成(部分读取), 参数:', params)
|
||||
console.error('讀取目錄未完成(部分讀取), 參數:', params)
|
||||
files.not_finished = true
|
||||
return files
|
||||
}
|
||||
@ -248,7 +265,7 @@ async function ls_folder ({ fid, not_teamdrive, service_account }) {
|
||||
}
|
||||
|
||||
async function gen_headers (use_sa) {
|
||||
use_sa = use_sa && SA_TOKENS.length
|
||||
// use_sa = use_sa && SA_TOKENS.length
|
||||
const access_token = use_sa ? (await get_sa_token()).access_token : (await get_access_token())
|
||||
return { authorization: 'Bearer ' + access_token }
|
||||
}
|
||||
@ -276,37 +293,30 @@ async function get_access_token () {
|
||||
return data.access_token
|
||||
}
|
||||
|
||||
// get_sa_token().catch(console.error)
|
||||
async function get_sa_token () {
|
||||
let tk
|
||||
if (!SA_TOKENS.length) SA_TOKENS = get_sa_batch()
|
||||
while (SA_TOKENS.length) {
|
||||
tk = get_random_element(SA_TOKENS)
|
||||
const tk = get_random_element(SA_TOKENS)
|
||||
try {
|
||||
return await real_get_sa_token(tk)
|
||||
} catch (e) {
|
||||
console.log(e)
|
||||
SA_TOKENS = SA_TOKENS.filter(v => v.gtoken !== tk.gtoken)
|
||||
if (!SA_TOKENS.length) SA_TOKENS = get_sa_batch()
|
||||
}
|
||||
}
|
||||
throw new Error('没有可用的SA帐号')
|
||||
throw new Error('沒有可用的SA帳號')
|
||||
}
|
||||
|
||||
function real_get_sa_token (el) {
|
||||
async function real_get_sa_token (el) {
|
||||
const { value, expires, gtoken } = el
|
||||
// 把gtoken传递出去的原因是当某账号流量用尽时可以依此过滤
|
||||
if (Date.now() < expires) return { access_token: value, gtoken }
|
||||
return new Promise((resolve, reject) => {
|
||||
gtoken.getToken((err, tokens) => {
|
||||
if (err) {
|
||||
reject(err)
|
||||
} else {
|
||||
// console.log('got sa token', tokens)
|
||||
const { access_token, expires_in } = tokens
|
||||
el.value = access_token
|
||||
el.expires = Date.now() + 1000 * expires_in
|
||||
resolve({ access_token, gtoken })
|
||||
}
|
||||
})
|
||||
})
|
||||
const { access_token, expires_in } = await gtoken.getToken({ forceRefresh: true })
|
||||
el.value = access_token
|
||||
el.expires = Date.now() + 1000 * (expires_in - 60 * 5) // 提前5分钟判定为过期
|
||||
return { access_token, gtoken }
|
||||
}
|
||||
|
||||
function get_random_element (arr) {
|
||||
@ -323,7 +333,7 @@ function validate_fid (fid) {
|
||||
return fid.match(reg)
|
||||
}
|
||||
|
||||
async function create_folder (name, parent, use_sa) {
|
||||
async function create_folder (name, parent, use_sa, limit) {
|
||||
let url = `https://www.googleapis.com/drive/v3/files`
|
||||
const params = { supportsAllDrives: true }
|
||||
url += '?' + params_to_query(params)
|
||||
@ -333,18 +343,34 @@ async function create_folder (name, parent, use_sa) {
|
||||
parents: [parent]
|
||||
}
|
||||
let retry = 0
|
||||
let data
|
||||
while (!data && (retry < RETRY_LIMIT)) {
|
||||
let err_message
|
||||
while (retry < RETRY_LIMIT) {
|
||||
try {
|
||||
const headers = await gen_headers(use_sa)
|
||||
data = (await axins.post(url, post_data, { headers })).data
|
||||
return (await axins.post(url, post_data, { headers })).data
|
||||
} catch (err) {
|
||||
err_message = err.message
|
||||
retry++
|
||||
handle_error(err)
|
||||
console.log('创建目录重试中:', name, '重试次数:', retry)
|
||||
const data = err && err.response && err.response.data
|
||||
const message = data && data.error && data.error.message
|
||||
if (message && message.toLowerCase().includes('file limit')) {
|
||||
if (limit) limit.clearQueue()
|
||||
throw new Error(FILE_EXCEED_MSG)
|
||||
}
|
||||
console.log('創建目錄重試中:', name, '重試次數:', retry)
|
||||
}
|
||||
}
|
||||
return data
|
||||
throw new Error(err_message + ' 目錄名:' + name)
|
||||
}
|
||||
|
||||
async function get_name_by_id (fid) {
|
||||
try {
|
||||
const { name } = await get_info_by_id(fid, true)
|
||||
return name
|
||||
} catch (e) {
|
||||
return fid
|
||||
}
|
||||
}
|
||||
|
||||
async function get_info_by_id (fid, use_sa) {
|
||||
@ -353,7 +379,7 @@ async function get_info_by_id (fid, use_sa) {
|
||||
includeItemsFromAllDrives: true,
|
||||
supportsAllDrives: true,
|
||||
corpora: 'allDrives',
|
||||
fields: 'id,name,owners'
|
||||
fields: 'id,name'
|
||||
}
|
||||
url += '?' + params_to_query(params)
|
||||
const headers = await gen_headers(use_sa)
|
||||
@ -365,10 +391,10 @@ async function user_choose () {
|
||||
const answer = await prompts({
|
||||
type: 'select',
|
||||
name: 'value',
|
||||
message: '检测到上次的复制记录,是否继续?',
|
||||
message: '檢測到上次的複製紀錄,是否繼續?',
|
||||
choices: [
|
||||
{ title: 'Continue', description: '从上次中断的地方继续', value: 'continue' },
|
||||
{ title: 'Restart', description: '无视已存在的记录,重新复制', value: 'restart' },
|
||||
{ title: 'Continue', description: '從上次中斷的地方繼續', value: 'continue' },
|
||||
{ title: 'Restart', description: '無視已存在的紀錄,重新複製', value: 'restart' },
|
||||
{ title: 'Exit', description: '直接退出', value: 'exit' }
|
||||
],
|
||||
initial: 0
|
||||
@ -376,25 +402,26 @@ async function user_choose () {
|
||||
return answer.value
|
||||
}
|
||||
|
||||
async function copy ({ source, target, name, min_size, update, not_teamdrive, service_account, is_server }) {
|
||||
async function copy ({ source, target, name, min_size, update, not_teamdrive, service_account, dncnr, is_server }) {
|
||||
target = target || DEFAULT_TARGET
|
||||
if (!target) throw new Error('目标位置不能为空')
|
||||
if (!target) throw new Error('目標位置不能為空')
|
||||
|
||||
const record = db.prepare('select id, status from task where source=? and target=?').get(source, target)
|
||||
if (record && record.status === 'copying') return console.log('已有相同源和目的地的任务正在运行,强制退出')
|
||||
if (record && record.status === 'copying') return console.log('已有相同來源和目的地的任務正在進行,強制退出')
|
||||
|
||||
try {
|
||||
return await real_copy({ source, target, name, min_size, update, not_teamdrive, service_account, is_server })
|
||||
return await real_copy({ source, target, name, min_size, update, dncnr, not_teamdrive, service_account, is_server })
|
||||
} catch (err) {
|
||||
console.error('复制文件夹出错', err)
|
||||
console.error('複製資料夾出錯', err)
|
||||
const record = db.prepare('select id, status from task where source=? and target=?').get(source, target)
|
||||
if (record) db.prepare('update task set status=? where id=?').run('error', record.id)
|
||||
}
|
||||
}
|
||||
|
||||
// 待解决:如果用户手动ctrl+c中断进程,那么已经发出的请求,就算完成了也不会记录到本地数据库中,所以可能产生重复文件(夹)
|
||||
async function real_copy ({ source, target, name, min_size, update, not_teamdrive, service_account, is_server }) {
|
||||
async function real_copy ({ source, target, name, min_size, update, dncnr, not_teamdrive, service_account, is_server }) {
|
||||
async function get_new_root () {
|
||||
if (dncnr) return { id: target }
|
||||
if (name) {
|
||||
return create_folder(name, target, service_account)
|
||||
} else {
|
||||
@ -405,14 +432,14 @@ async function real_copy ({ source, target, name, min_size, update, not_teamdriv
|
||||
|
||||
const record = db.prepare('select * from task where source=? and target=?').get(source, target)
|
||||
if (record) {
|
||||
const copied = db.prepare('select fileid from copied where taskid=?').all(record.id).map(v => v.fileid)
|
||||
const choice = is_server ? 'continue' : await user_choose()
|
||||
if (choice === 'exit') {
|
||||
return console.log('退出程序')
|
||||
} else if (choice === 'continue') {
|
||||
let { copied, mapping } = record
|
||||
const copied_ids = {}
|
||||
let { mapping } = record
|
||||
const old_mapping = {}
|
||||
copied = copied.trim().split('\n')
|
||||
const copied_ids = {}
|
||||
copied.forEach(id => copied_ids[id] = true)
|
||||
mapping = mapping.trim().split('\n').map(line => line.split(' '))
|
||||
const root = mapping[0][1]
|
||||
@ -421,9 +448,9 @@ async function real_copy ({ source, target, name, min_size, update, not_teamdriv
|
||||
const arr = await walk_and_save({ fid: source, update, not_teamdrive, service_account })
|
||||
let files = arr.filter(v => v.mimeType !== FOLDER_TYPE).filter(v => !copied_ids[v.id])
|
||||
if (min_size) files = files.filter(v => v.size >= min_size)
|
||||
const folders = arr.filter(v => v.mimeType === FOLDER_TYPE).filter(v => !old_mapping[v.id])
|
||||
console.log('待复制的目录数:', folders.length)
|
||||
console.log('待复制的文件数:', files.length)
|
||||
const folders = arr.filter(v => v.mimeType === FOLDER_TYPE)
|
||||
console.log('待複製的目錄數:', folders.length)
|
||||
console.log('待複製的檔案數:', files.length)
|
||||
const all_mapping = await create_folders({
|
||||
old_mapping,
|
||||
source,
|
||||
@ -432,21 +459,22 @@ async function real_copy ({ source, target, name, min_size, update, not_teamdriv
|
||||
root,
|
||||
task_id: record.id
|
||||
})
|
||||
await copy_files({ files, mapping: all_mapping, root, task_id: record.id })
|
||||
await copy_files({ files, service_account, root, mapping: all_mapping, task_id: record.id })
|
||||
db.prepare('update task set status=?, ftime=? where id=?').run('finished', Date.now(), record.id)
|
||||
return { id: root }
|
||||
return { id: root, task_id: record.id }
|
||||
} else if (choice === 'restart') {
|
||||
const new_root = await get_new_root()
|
||||
if (!new_root) throw new Error('创建目录失败,请检查您的帐号是否有相应的权限')
|
||||
const root_mapping = source + ' ' + new_root.id + '\n'
|
||||
db.prepare('update task set status=?, copied=?, mapping=? where id=?')
|
||||
.run('copying', '', root_mapping, record.id)
|
||||
const arr = await walk_and_save({ fid: source, update: true, not_teamdrive, service_account })
|
||||
db.prepare('update task set status=?, mapping=? where id=?').run('copying', root_mapping, record.id)
|
||||
db.prepare('delete from copied where taskid=?').run(record.id)
|
||||
// const arr = await walk_and_save({ fid: source, update: true, not_teamdrive, service_account })
|
||||
const arr = await walk_and_save({ fid: source, update, not_teamdrive, service_account })
|
||||
|
||||
let files = arr.filter(v => v.mimeType !== FOLDER_TYPE)
|
||||
if (min_size) files = files.filter(v => v.size >= min_size)
|
||||
const folders = arr.filter(v => v.mimeType === FOLDER_TYPE)
|
||||
console.log('待复制的目录数:', folders.length)
|
||||
console.log('待复制的文件数:', files.length)
|
||||
console.log('待複製的目錄數:', folders.length)
|
||||
console.log('待複製的檔案數:', files.length)
|
||||
const mapping = await create_folders({
|
||||
source,
|
||||
folders,
|
||||
@ -454,24 +482,23 @@ async function real_copy ({ source, target, name, min_size, update, not_teamdriv
|
||||
root: new_root.id,
|
||||
task_id: record.id
|
||||
})
|
||||
await copy_files({ files, mapping, root: new_root.id, task_id: record.id })
|
||||
await copy_files({ files, mapping, service_account, root: new_root.id, task_id: record.id })
|
||||
db.prepare('update task set status=?, ftime=? where id=?').run('finished', Date.now(), record.id)
|
||||
return new_root
|
||||
return { id: new_root.id, task_id: record.id }
|
||||
} else {
|
||||
// ctrl+c 退出
|
||||
return console.log('退出程序')
|
||||
}
|
||||
} else {
|
||||
const new_root = await get_new_root()
|
||||
if (!new_root) throw new Error('创建目录失败,请检查您的帐号是否有相应的权限')
|
||||
const root_mapping = source + ' ' + new_root.id + '\n'
|
||||
const { lastInsertRowid } = db.prepare('insert into task (source, target, status, mapping, ctime) values (?, ?, ?, ?, ?)').run(source, target, 'copying', root_mapping, Date.now())
|
||||
const arr = await walk_and_save({ fid: source, update, not_teamdrive, service_account })
|
||||
let files = arr.filter(v => v.mimeType !== FOLDER_TYPE)
|
||||
if (min_size) files = files.filter(v => v.size >= min_size)
|
||||
const folders = arr.filter(v => v.mimeType === FOLDER_TYPE)
|
||||
console.log('待复制的目录数:', folders.length)
|
||||
console.log('待复制的文件数:', files.length)
|
||||
console.log('待複製的目錄數:', folders.length)
|
||||
console.log('待複製的檔案數:', files.length)
|
||||
const mapping = await create_folders({
|
||||
source,
|
||||
folders,
|
||||
@ -479,39 +506,33 @@ async function real_copy ({ source, target, name, min_size, update, not_teamdriv
|
||||
root: new_root.id,
|
||||
task_id: lastInsertRowid
|
||||
})
|
||||
await copy_files({ files, mapping, root: new_root.id, task_id: lastInsertRowid })
|
||||
await copy_files({ files, mapping, service_account, root: new_root.id, task_id: lastInsertRowid })
|
||||
db.prepare('update task set status=?, ftime=? where id=?').run('finished', Date.now(), lastInsertRowid)
|
||||
return new_root
|
||||
return { id: new_root.id, task_id: lastInsertRowid }
|
||||
}
|
||||
}
|
||||
|
||||
async function copy_files ({ files, mapping, root, task_id }) {
|
||||
console.log('\n开始复制文件,总数:', files.length)
|
||||
async function copy_files ({ files, mapping, service_account, root, task_id }) {
|
||||
console.log('\n開始複製文件,總數:', files.length)
|
||||
const limit = pLimit(PARALLEL_LIMIT)
|
||||
let count = 0
|
||||
const loop = setInterval(() => {
|
||||
const now = dayjs().format('HH:mm:ss')
|
||||
const message = `${now} | 已复制文件数 ${count} | 排队等候的网络请求 ${limit.pendingCount}`
|
||||
const message = `${now} | 已複製的檔案數 ${count} | 網路請求 進行中${limit.activeCount}/排隊中${limit.pendingCount}`
|
||||
print_progress(message)
|
||||
}, 1000)
|
||||
await Promise.all(files.map(async file => {
|
||||
try {
|
||||
const { id, parent } = file
|
||||
const target = mapping[parent] || root
|
||||
const new_file = await limit(() => copy_file(id, target))
|
||||
if (new_file) {
|
||||
db.prepare('update task set status=?, copied = copied || ? where id=?')
|
||||
.run('copying', id + '\n', task_id)
|
||||
}
|
||||
return Promise.all(files.map(async file => {
|
||||
const { id, parent } = file
|
||||
const target = mapping[parent] || root
|
||||
const new_file = await limit(() => copy_file(id, target, service_account, limit, task_id))
|
||||
if (new_file) {
|
||||
count++
|
||||
} catch (e) {
|
||||
console.error(e)
|
||||
db.prepare('INSERT INTO copied (taskid, fileid) VALUES (?, ?)').run(task_id, id)
|
||||
}
|
||||
}))
|
||||
clearInterval(loop)
|
||||
})).finally(() => clearInterval(loop))
|
||||
}
|
||||
|
||||
async function copy_file (id, parent) {
|
||||
async function copy_file (id, parent, use_sa, limit, task_id) {
|
||||
let url = `https://www.googleapis.com/drive/v3/files/${id}/copy`
|
||||
let params = { supportsAllDrives: true }
|
||||
url += '?' + params_to_query(params)
|
||||
@ -519,7 +540,7 @@ async function copy_file (id, parent) {
|
||||
let retry = 0
|
||||
while (retry < RETRY_LIMIT) {
|
||||
let gtoken
|
||||
if (SA_TOKENS.length) { // 如果有sa文件则优先使用
|
||||
if (use_sa) {
|
||||
const temp = await get_sa_token()
|
||||
gtoken = temp.gtoken
|
||||
config.headers = { authorization: 'Bearer ' + temp.access_token }
|
||||
@ -534,16 +555,24 @@ async function copy_file (id, parent) {
|
||||
handle_error(err)
|
||||
const data = err && err.response && err.response.data
|
||||
const message = data && data.error && data.error.message
|
||||
if (message && message.toLowerCase().includes('rate limit')) {
|
||||
if (message && message.toLowerCase().includes('file limit')) {
|
||||
if (limit) limit.clearQueue()
|
||||
if (task_id) db.prepare('update task set status=? where id=?').run('error', task_id)
|
||||
throw new Error('您的小組雲端硬碟文件數已超限,停止複製')
|
||||
}
|
||||
if (use_sa && message && message.toLowerCase().includes('rate limit')) {
|
||||
SA_TOKENS = SA_TOKENS.filter(v => v.gtoken !== gtoken)
|
||||
console.log('此帐号触发使用限额,剩余可用service account帐号数量:', SA_TOKENS.length)
|
||||
if (!SA_TOKENS.length) SA_TOKENS = get_sa_batch()
|
||||
console.log('此帳號觸發使用限額,剩餘可用service account帳號數量:', SA_TOKENS.length)
|
||||
}
|
||||
}
|
||||
}
|
||||
if (!SA_TOKENS.length) {
|
||||
throw new Error('所有SA帐号流量已用完')
|
||||
if (use_sa && !SA_TOKENS.length) {
|
||||
if (limit) limit.clearQueue()
|
||||
if (task_id) db.prepare('update task set status=? where id=?').run('error', task_id)
|
||||
throw new Error('所有SA帳號流量已用完')
|
||||
} else {
|
||||
console.warn('复制文件失败,文件id: ' + id)
|
||||
console.warn('複製檔案失敗,檔案id: ' + id)
|
||||
}
|
||||
}
|
||||
|
||||
@ -553,33 +582,38 @@ async function create_folders ({ source, old_mapping, folders, root, task_id, se
|
||||
mapping[source] = root
|
||||
if (!folders.length) return mapping
|
||||
|
||||
console.log('开始复制文件夹,总数:', folders.length)
|
||||
const missed_folders = folders.filter(v => !mapping[v.id])
|
||||
console.log('開始複製資料夾,總數:', missed_folders.length)
|
||||
const limit = pLimit(PARALLEL_LIMIT)
|
||||
let count = 0
|
||||
let same_levels = folders.filter(v => v.parent === folders[0].parent)
|
||||
|
||||
const loop = setInterval(() => {
|
||||
const now = dayjs().format('HH:mm:ss')
|
||||
const message = `${now} | 已创建目录数 ${count} | 排队等候的网络请求 ${limit.pendingCount}`
|
||||
const message = `${now} | 已創建目錄 ${count} | 網路請求 進行中${limit.activeCount}/排隊中${limit.pendingCount}`
|
||||
print_progress(message)
|
||||
}, 1000)
|
||||
|
||||
while (same_levels.length) {
|
||||
await Promise.all(same_levels.map(async v => {
|
||||
const same_levels_missed = same_levels.filter(v => !mapping[v.id])
|
||||
await Promise.all(same_levels_missed.map(async v => {
|
||||
try {
|
||||
const { name, id, parent } = v
|
||||
const target = mapping[parent] || root
|
||||
const new_folder = await limit(() => create_folder(name, target, service_account))
|
||||
if (!new_folder) throw new Error(name + '创建失败')
|
||||
const new_folder = await limit(() => create_folder(name, target, service_account, limit))
|
||||
count++
|
||||
mapping[id] = new_folder.id
|
||||
const mapping_record = id + ' ' + new_folder.id + '\n'
|
||||
db.prepare('update task set status=?, mapping = mapping || ? where id=?').run('copying', mapping_record, task_id)
|
||||
db.prepare('update task set mapping = mapping || ? where id=?').run(mapping_record, task_id)
|
||||
} catch (e) {
|
||||
console.error('创建目录出错:', v, e)
|
||||
if (e.message === FILE_EXCEED_MSG) {
|
||||
clearInterval(loop)
|
||||
throw new Error(FILE_EXCEED_MSG)
|
||||
}
|
||||
console.error('創建目錄出錯:', e.message)
|
||||
}
|
||||
}))
|
||||
folders = folders.filter(v => !mapping[v.id])
|
||||
// folders = folders.filter(v => !mapping[v.id])
|
||||
same_levels = [].concat(...same_levels.map(v => folders.filter(vv => vv.parent === v.id)))
|
||||
}
|
||||
|
||||
@ -627,17 +661,24 @@ async function confirm_dedupe ({ file_number, folder_number }) {
|
||||
const answer = await prompts({
|
||||
type: 'select',
|
||||
name: 'value',
|
||||
message: `检测到重复文件${file_number}个,重复目录${folder_number}个,是否删除?`,
|
||||
message: `檢測到同位置下重複文件${file_number}个,重複空目錄${folder_number}個,是否刪除?`,
|
||||
choices: [
|
||||
{ title: 'Yes', description: '确认删除', value: 'yes' },
|
||||
{ title: 'No', description: '先不删除', value: 'no' }
|
||||
{ title: 'Yes', description: '確認刪除', value: 'yes' },
|
||||
{ title: 'No', description: '先不刪除', value: 'no' }
|
||||
],
|
||||
initial: 0
|
||||
})
|
||||
return answer.value
|
||||
}
|
||||
|
||||
// 可以删除文件或文件夹,似乎不会进入回收站
|
||||
// 将文件或文件夹移入回收站,需要 sa 为 content manager 权限及以上
|
||||
async function trash_file ({ fid, service_account }) {
|
||||
const url = `https://www.googleapis.com/drive/v3/files/${fid}?supportsAllDrives=true`
|
||||
const headers = await gen_headers(service_account)
|
||||
return axins.patch(url, { trashed: true }, { headers })
|
||||
}
|
||||
|
||||
// 直接删除文件或文件夹,不会进入回收站,需要 sa 为 manager 权限
|
||||
async function rm_file ({ fid, service_account }) {
|
||||
const headers = await gen_headers(service_account)
|
||||
let retry = 0
|
||||
@ -648,7 +689,7 @@ async function rm_file ({ fid, service_account }) {
|
||||
} catch (err) {
|
||||
retry++
|
||||
handle_error(err)
|
||||
console.log('删除重试中,重试次数', retry)
|
||||
console.log('刪除重試中,重試次數', retry)
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -658,7 +699,7 @@ async function dedupe ({ fid, update, service_account }) {
|
||||
if (!update) {
|
||||
const info = get_all_by_fid(fid)
|
||||
if (info) {
|
||||
console.log('找到本地缓存数据,缓存时间:', dayjs(info.mtime).format('YYYY-MM-DD HH:mm:ss'))
|
||||
console.log('找到本地快取資料,快取時間:', dayjs(info.mtime).format('YYYY-MM-DD HH:mm:ss'))
|
||||
arr = info
|
||||
}
|
||||
}
|
||||
@ -677,16 +718,16 @@ async function dedupe ({ fid, update, service_account }) {
|
||||
let file_count = 0
|
||||
await Promise.all(dupes.map(async v => {
|
||||
try {
|
||||
await limit(() => rm_file({ fid: v.id, service_account }))
|
||||
await limit(() => trash_file({ fid: v.id, service_account }))
|
||||
if (v.mimeType === FOLDER_TYPE) {
|
||||
console.log('成功删除文件夹', v.name)
|
||||
console.log('成功刪除資料夾', v.name)
|
||||
folder_count++
|
||||
} else {
|
||||
console.log('成功删除文件', v.name)
|
||||
console.log('成功刪除檔案', v.name)
|
||||
file_count++
|
||||
}
|
||||
} catch (e) {
|
||||
console.log('删除失败', e.message)
|
||||
console.log('刪除失敗', e.message)
|
||||
}
|
||||
}))
|
||||
return { file_count, folder_count }
|
||||
@ -704,10 +745,10 @@ function handle_error (err) {
|
||||
function print_progress (msg) {
|
||||
if (process.stdout.cursorTo) {
|
||||
process.stdout.cursorTo(0)
|
||||
process.stdout.write(msg)
|
||||
process.stdout.write(msg + ' ')
|
||||
} else {
|
||||
console.log(msg)
|
||||
}
|
||||
}
|
||||
|
||||
module.exports = { ls_folder, count, validate_fid, copy, dedupe, copy_file, gen_count_body, real_copy }
|
||||
module.exports = { ls_folder, count, validate_fid, copy, dedupe, copy_file, gen_count_body, real_copy, get_name_by_id }
|
||||
|
||||
@ -2,21 +2,26 @@ const Router = require('@koa/router')
|
||||
|
||||
const { db } = require('../db')
|
||||
const { validate_fid, gen_count_body } = require('./gd')
|
||||
const { send_count, send_help, send_choice, send_task_info, sm, extract_fid, reply_cb_query, tg_copy, send_all_tasks } = require('./tg')
|
||||
const { send_count, send_help, send_choice, send_task_info, sm, extract_fid, extract_from_text, reply_cb_query, tg_copy, send_all_tasks, send_bm_help, get_target_by_alias, send_all_bookmarks, set_bookmark, unset_bookmark } = require('./tg')
|
||||
|
||||
const { AUTH } = require('../config')
|
||||
const { AUTH, ROUTER_PASSKEY, TG_IPLIST } = require('../config')
|
||||
const { tg_whitelist } = AUTH
|
||||
|
||||
const COPYING_FIDS = {}
|
||||
const counting = {}
|
||||
const router = new Router()
|
||||
|
||||
router.get('/api/gdurl/count', async ctx => {
|
||||
if (!ROUTER_PASSKEY) return ctx.body = 'gd-utils-cht 成功啟動'
|
||||
const { query, headers } = ctx.request
|
||||
let { fid, type, update } = query
|
||||
if (!validate_fid(fid)) throw new Error('无效的分享ID')
|
||||
let { fid, type, update, passkey } = query
|
||||
if (passkey !== ROUTER_PASSKEY) return ctx.body = 'invalid passkey'
|
||||
if (!validate_fid(fid)) throw new Error('無效的分享ID')
|
||||
|
||||
let ua = headers['user-agent'] || ''
|
||||
ua = ua.toLowerCase()
|
||||
type = (type || '').toLowerCase()
|
||||
// todo type=tree
|
||||
if (!type) {
|
||||
if (ua.includes('curl')) {
|
||||
type = 'curl'
|
||||
@ -38,6 +43,7 @@ router.post('/api/gdurl/tgbot', async ctx => {
|
||||
const { body } = ctx.request
|
||||
console.log('ctx.ip', ctx.ip) // 可以只允许tg服务器的ip
|
||||
console.log('tg message:', body)
|
||||
if (TG_IPLIST && !TG_IPLIST.includes(ctx.ip)) return ctx.body = 'invalid ip'
|
||||
ctx.body = '' // 早点释放连接
|
||||
const message = body.message || body.edited_message
|
||||
|
||||
@ -45,54 +51,76 @@ router.post('/api/gdurl/tgbot', async ctx => {
|
||||
if (callback_query) {
|
||||
const { id, data } = callback_query
|
||||
const chat_id = callback_query.from.id
|
||||
const [action, fid] = data.split(' ')
|
||||
const [action, fid, target] = data.split(' ')
|
||||
if (action === 'count') {
|
||||
if (counting[fid]) return sm({ chat_id, text: fid + ' 正在统计,请稍等片刻' })
|
||||
if (counting[fid]) return sm({ chat_id, text: fid + ' 正在統計,請稍候' })
|
||||
counting[fid] = true
|
||||
send_count({ fid, chat_id }).catch(err => {
|
||||
console.error(err)
|
||||
sm({ chat_id, text: fid + ' 统计失败:' + err.message })
|
||||
sm({ chat_id, text: fid + ' 統計失敗:' + err.message })
|
||||
}).finally(() => {
|
||||
delete counting[fid]
|
||||
})
|
||||
} else if (action === 'copy') {
|
||||
tg_copy({ fid, chat_id }).then(task_id => {
|
||||
task_id && sm({ chat_id, text: `开始复制,任务ID: ${task_id} 可输入 /task ${task_id} 查询进度` })
|
||||
})
|
||||
if (COPYING_FIDS[fid]) return sm({ chat_id, text: `正在處理 ${fid} 的複製命令` })
|
||||
COPYING_FIDS[fid] = true
|
||||
tg_copy({ fid, target: get_target_by_alias(target), chat_id }).then(task_id => {
|
||||
task_id && sm({ chat_id, text: `開始複製,任務ID: ${task_id} 可輸入 /task ${task_id} 查詢進度` })
|
||||
}).finally(() => COPYING_FIDS[fid] = false)
|
||||
}
|
||||
return reply_cb_query({ id, data }).catch(console.error)
|
||||
}
|
||||
|
||||
const chat_id = message && message.chat && message.chat.id
|
||||
const text = message && message.text && message.text.trim()
|
||||
const username = message && message.from && message.from.username
|
||||
if (!chat_id || !text || !tg_whitelist.includes(username)) return console.warn('异常请求')
|
||||
let username = message && message.from && message.from.username
|
||||
username = username && String(username).toLowerCase()
|
||||
let user_id = message && message.from && message.from.id
|
||||
user_id = user_id && String(user_id).toLowerCase()
|
||||
if (!chat_id || !text || !tg_whitelist.some(v => {
|
||||
v = String(v).toLowerCase()
|
||||
return v === username || v === user_id
|
||||
})) return console.warn('異常請求')
|
||||
|
||||
const fid = extract_fid(text)
|
||||
const no_fid_commands = ['/task', '/help']
|
||||
const fid = extract_fid(text) || extract_from_text(text)
|
||||
const no_fid_commands = ['/task', '/help', '/bm']
|
||||
if (!no_fid_commands.some(cmd => text.startsWith(cmd)) && !validate_fid(fid)) {
|
||||
return sm({ chat_id, text: '未识别出分享ID' })
|
||||
return sm({ chat_id, text: '未辨識到分享ID' })
|
||||
}
|
||||
if (text.startsWith('/help')) return send_help(chat_id)
|
||||
if (text.startsWith('https://drive.google.com/')) {
|
||||
return send_choice({ fid, chat_id }).catch(console.error)
|
||||
}
|
||||
if (text.startsWith('/count')) {
|
||||
if (counting[fid]) return sm({ chat_id, text: fid + ' 正在统计,请稍等片刻' })
|
||||
if (text.startsWith('/bm')) {
|
||||
const [cmd, action, alias, target] = text.split(' ').map(v => v.trim())
|
||||
if (!action) return send_all_bookmarks(chat_id)
|
||||
if (action === 'set') {
|
||||
if (!alias || !target) return sm({ chat_id, text: '標籤名和dstID不能為空' })
|
||||
if (alias.length > 24) return sm({ chat_id, text: '標籤名請勿超過24个英文字符' })
|
||||
if (!validate_fid(target)) return sm({ chat_id, text: 'dstID格式錯誤' })
|
||||
set_bookmark({ chat_id, alias, target })
|
||||
} else if (action === 'unset') {
|
||||
if (!alias) return sm({ chat_id, text: '標籤名不能為空' })
|
||||
unset_bookmark({ chat_id, alias })
|
||||
} else {
|
||||
send_bm_help(chat_id)
|
||||
}
|
||||
} else if (text.startsWith('/count')) {
|
||||
if (counting[fid]) return sm({ chat_id, text: fid + ' 正在統計,請稍候' })
|
||||
try {
|
||||
counting[fid] = true
|
||||
await send_count({ fid, chat_id })
|
||||
const update = text.endsWith(' -u')
|
||||
await send_count({ fid, chat_id, update })
|
||||
} catch (err) {
|
||||
console.error(err)
|
||||
sm({ chat_id, text: fid + ' 统计失败:' + err.message })
|
||||
sm({ chat_id, text: fid + ' 統計失敗:' + err.message })
|
||||
} finally {
|
||||
delete counting[fid]
|
||||
}
|
||||
} else if (text.startsWith('/copy')) {
|
||||
const target = text.replace('/copy', '').trim().split(' ').map(v => v.trim())[1]
|
||||
if (target && !validate_fid(target)) return sm({ chat_id, text: `目标ID ${target} 格式不正确` })
|
||||
tg_copy({ fid, target, chat_id }).then(task_id => {
|
||||
task_id && sm({ chat_id, text: `开始复制,任务ID: ${task_id} 可输入 /task ${task_id} 查询进度` })
|
||||
let target = text.replace('/copy', '').replace(' -u', '').trim().split(' ').map(v => v.trim())[1]
|
||||
target = get_target_by_alias(target) || target
|
||||
if (target && !validate_fid(target)) return sm({ chat_id, text: `目標ID ${target} 格式不正確` })
|
||||
const update = text.endsWith(' -u')
|
||||
tg_copy({ fid, target, chat_id, update }).then(task_id => {
|
||||
task_id && sm({ chat_id, text: `開始複製,任務ID: ${task_id} 可輸入 /task ${task_id} 查詢進度` })
|
||||
})
|
||||
} else if (text.startsWith('/task')) {
|
||||
let task_id = text.replace('/task', '').trim()
|
||||
@ -102,12 +130,14 @@ router.post('/api/gdurl/tgbot', async ctx => {
|
||||
task_id = parseInt(task_id)
|
||||
if (!task_id) {
|
||||
const running_tasks = db.prepare('select id from task where status=?').all('copying')
|
||||
if (!running_tasks.length) return sm({ chat_id, text: '当前暂无运行中的任务' })
|
||||
if (!running_tasks.length) return sm({ chat_id, text: '目前沒有執行中的任務' })
|
||||
return running_tasks.forEach(v => send_task_info({ chat_id, task_id: v.id }).catch(console.error))
|
||||
}
|
||||
send_task_info({ task_id, chat_id }).catch(console.error)
|
||||
} else if (text.includes('drive.google.com/') || validate_fid(text)) {
|
||||
return send_choice({ fid: fid || text, chat_id }).catch(console.error)
|
||||
} else {
|
||||
sm({ chat_id, text: '暂不支持此命令' })
|
||||
sm({ chat_id, text: '暫不支持此命令' })
|
||||
}
|
||||
})
|
||||
|
||||
|
||||
@ -5,10 +5,10 @@ const { escape } = require('html-escaper')
|
||||
module.exports = { make_table, summary, make_html, make_tg_table }
|
||||
|
||||
function make_html ({ file_count, folder_count, total_size, details }) {
|
||||
const head = ['类型', '数量', '大小']
|
||||
const head = ['類型', '數量', '大小']
|
||||
const th = '<tr>' + head.map(k => `<th>${k}</th>`).join('') + '</tr>'
|
||||
const td = details.map(v => '<tr>' + [escape(v.ext), v.count, v.size].map(k => `<td>${k}</td>`).join('') + '</tr>').join('')
|
||||
let tail = ['合计', file_count + folder_count, total_size]
|
||||
let tail = ['合計', file_count + folder_count, total_size]
|
||||
tail = '<tr style="font-weight:bold">' + tail.map(k => `<td>${k}</td>`).join('') + '</tr>'
|
||||
const table = `<table border="1" cellpadding="12" style="border-collapse:collapse;font-family:serif;font-size:22px;margin:10px auto;text-align: center">
|
||||
${th}
|
||||
@ -26,7 +26,7 @@ function make_table ({ file_count, folder_count, total_size, details }) {
|
||||
return arr.map(content => ({ content, hAlign }))
|
||||
})
|
||||
const total_count = file_count + folder_count
|
||||
const tails = ['总计', total_count, total_size].map(v => ({ content: colors.bold(v), hAlign }))
|
||||
const tails = ['總計', total_count, total_size].map(v => ({ content: colors.bold(v), hAlign }))
|
||||
tb.push(headers, ...records)
|
||||
tb.push(tails)
|
||||
return tb.toString() + '\n'
|
||||
@ -56,8 +56,8 @@ function make_tg_table ({ file_count, folder_count, total_size, details }) {
|
||||
const hAlign = 'center'
|
||||
const headers = ['Type', 'Count', 'Size'].map(v => ({ content: v, hAlign }))
|
||||
details.forEach(v => {
|
||||
if (v.ext === '文件夹') v.ext = '[Folder]'
|
||||
if (v.ext === '无扩展名') v.ext = '[NoExt]'
|
||||
if (v.ext === '資料夾') v.ext = '[Folder]'
|
||||
if (v.ext === '無副檔名') v.ext = '[NoExt]'
|
||||
})
|
||||
const records = details.map(v => [v.ext, v.count, v.size]).map(arr => arr.map(content => ({ content, hAlign })))
|
||||
const total_count = file_count + folder_count
|
||||
@ -107,8 +107,8 @@ function summary (info, sort_by) {
|
||||
} else {
|
||||
details.sort((a, b) => b.count - a.count)
|
||||
}
|
||||
if (no_ext) details.push({ ext: '无扩展名', count: no_ext, size: format_size(no_ext_size), raw_size: no_ext_size })
|
||||
if (folder_count) details.push({ ext: '文件夹', count: folder_count, size: 0, raw_size: 0 })
|
||||
if (no_ext) details.push({ ext: '無副檔名', count: no_ext, size: format_size(no_ext_size), raw_size: no_ext_size })
|
||||
if (folder_count) details.push({ ext: '資料夾', count: folder_count, size: 0, raw_size: 0 })
|
||||
return { file_count, folder_count, total_size, details }
|
||||
}
|
||||
|
||||
|
||||
292
src/tg.js
292
src/tg.js
@ -4,49 +4,151 @@ const axios = require('@viegg/axios')
|
||||
const HttpsProxyAgent = require('https-proxy-agent')
|
||||
|
||||
const { db } = require('../db')
|
||||
const { gen_count_body, validate_fid, real_copy } = require('./gd')
|
||||
const { AUTH, DEFAULT_TARGET } = require('../config')
|
||||
const { gen_count_body, validate_fid, real_copy, get_name_by_id } = require('./gd')
|
||||
const { AUTH, DEFAULT_TARGET, USE_PERSONAL_AUTH } = require('../config')
|
||||
const { tg_token } = AUTH
|
||||
const gen_link = (fid, text) => `<a href="https://drive.google.com/drive/folders/${fid}">${text || fid}</a>`
|
||||
|
||||
if (!tg_token) throw new Error('请先在auth.js里设置tg_token')
|
||||
if (!tg_token) throw new Error('請先在config.js中設定tg_token')
|
||||
const { https_proxy } = process.env
|
||||
const axins = axios.create(https_proxy ? { httpsAgent: new HttpsProxyAgent(https_proxy) } : {})
|
||||
|
||||
module.exports = { send_count, send_help, sm, extract_fid, reply_cb_query, send_choice, send_task_info, send_all_tasks, tg_copy }
|
||||
const FID_TO_NAME = {}
|
||||
|
||||
async function get_folder_name (fid) {
|
||||
let name = FID_TO_NAME[fid]
|
||||
if (name) return name
|
||||
name = await get_name_by_id(fid)
|
||||
return FID_TO_NAME[fid] = name
|
||||
}
|
||||
|
||||
function send_help (chat_id) {
|
||||
const text = `<pre>[使用帮助]
|
||||
命令 | 说明
|
||||
|
||||
/help | 返回本条使用说明
|
||||
|
||||
/count shareID | 返回sourceID的文件统计信息, sourceID可以是google drive分享网址本身,也可以是分享ID
|
||||
|
||||
/copy sourceID targetID | 将sourceID的文件复制到targetID里(会新建一个文件夹),若不填targetID,则会复制到默认位置(在config.js里设置)。返回拷贝任务的taskID
|
||||
|
||||
/task taskID | 返回对应任务的进度信息,若不填则返回所有正在运行的任务进度,若填 all 则返回所有任务列表
|
||||
const text = `<pre>[使用說明]
|
||||
***不支持單檔分享***
|
||||
命令 | 說明
|
||||
=====================
|
||||
/help | 返回本使用說明
|
||||
=====================
|
||||
/count sourceID [-u] | 返回sourceID的文件統計資訊
|
||||
sourceID可以是共享網址本身,也可以是共享ID。如果命令最后加上 -u,則無視快取記錄強制從線上獲取,適合一段時候後才更新完畢的分享連結。
|
||||
=====================
|
||||
/copy sourceID targetID(選填) [-u] | 將sourceID的文件複製到targetID裡(會新建一個資料夾)
|
||||
若無targetID,則會複製到預設位置(config.js中的DEFAULT_TARGET)。
|
||||
如果設定了bookmark,那麼targetID也可以是bookmark的標籤名。
|
||||
如果命令最後加上 -u,則無視快取記錄強制從線上獲取源資料夾資訊。返回拷貝任務的taskID
|
||||
=====================
|
||||
/task taskID(選填) | 返回對應任務的進度信息,若不填taskID則返回所有正在運行的任務進度
|
||||
若填 all 則返回所有任務列表(歷史紀錄)
|
||||
=====================
|
||||
/bm [action] [alias] [target] | bookmark,添加常用目的資料夾ID
|
||||
會在輸入共享連結後返回的「文件統計」「開始複製」這兩個按鈕的下方出現,方便複製到常用位置。
|
||||
範例:
|
||||
/bm | 返回所有設定的資料夾
|
||||
/bm set movie folder-id | 將folder-id加入到收藏夾,標籤名設為movie
|
||||
/bm unset movie | 刪除此收藏夾
|
||||
</pre>`
|
||||
return sm({ chat_id, text, parse_mode: 'HTML' })
|
||||
}
|
||||
|
||||
function send_bm_help (chat_id) {
|
||||
const text = `<pre>/bm [action] [alias] [target] | bookmark,添加常用目的資料夾ID
|
||||
會在輸入共享連結後返回的「文件統計」「開始複製」這兩個按鈕的下方出現,方便複製到常用位置。
|
||||
範例:
|
||||
/bm | 返回所有設定的資料夾
|
||||
/bm set movie folder-id | 將folder-id加入到收藏夾,標籤名設為movie
|
||||
/bm unset movie | 刪除此收藏夾
|
||||
</pre>`
|
||||
return sm({ chat_id, text, parse_mode: 'HTML' })
|
||||
}
|
||||
|
||||
function send_all_bookmarks (chat_id) {
|
||||
let records = db.prepare('select alias, target from bookmark').all()
|
||||
if (!records.length) return sm({ chat_id, text: '資料庫中沒有收藏紀錄' })
|
||||
const tb = new Table({ style: { head: [], border: [] } })
|
||||
const headers = ['標籤名', 'dstID']
|
||||
records = records.map(v => [v.alias, v.target])
|
||||
tb.push(headers, ...records)
|
||||
const text = tb.toString().replace(/─/g, '—')
|
||||
return sm({ chat_id, text: `<pre>${text}</pre>`, parse_mode: 'HTML' })
|
||||
}
|
||||
|
||||
function set_bookmark ({ chat_id, alias, target }) {
|
||||
const record = db.prepare('select alias from bookmark where alias=?').get(alias)
|
||||
if (record) return sm({ chat_id, text: '資料庫中已有同名的收藏' })
|
||||
db.prepare('INSERT INTO bookmark (alias, target) VALUES (?, ?)').run(alias, target)
|
||||
return sm({ chat_id, text: `成功設定收藏${alias} | ${target}` })
|
||||
}
|
||||
|
||||
function unset_bookmark ({ chat_id, alias }) {
|
||||
const record = db.prepare('select alias from bookmark where alias=?').get(alias)
|
||||
if (!record) return sm({ chat_id, text: '未找到此標籤名的收藏' })
|
||||
db.prepare('delete from bookmark where alias=?').run(alias)
|
||||
return sm({ chat_id, text: '成功刪除收藏 ' + alias })
|
||||
}
|
||||
|
||||
function get_target_by_alias (alias) {
|
||||
const record = db.prepare('select target from bookmark where alias=?').get(alias)
|
||||
return record && record.target
|
||||
}
|
||||
|
||||
function send_choice ({ fid, chat_id }) {
|
||||
return sm({
|
||||
if(BUTTON_LEVEL == 1){
|
||||
return sm({
|
||||
chat_id,
|
||||
text: `识别出分享ID ${fid},请选择动作`,
|
||||
text: `辨識到分享ID ${fid},請選擇動作`,
|
||||
reply_markup: {
|
||||
inline_keyboard: [
|
||||
[
|
||||
{ text: '文件统计', callback_data: `count ${fid}` },
|
||||
{ text: '开始复制', callback_data: `copy ${fid}` }
|
||||
{ text: '文件統計', callback_data: `count ${fid}` }
|
||||
],
|
||||
[
|
||||
{ text: '開始複製', callback_data: `copy ${fid}` }
|
||||
]
|
||||
]
|
||||
].concat(gen_bookmark_choices(fid))
|
||||
}
|
||||
})
|
||||
})
|
||||
}else{
|
||||
return sm({
|
||||
chat_id,
|
||||
text: `辨識到分享ID ${fid},請選擇動作`,
|
||||
reply_markup: {
|
||||
inline_keyboard: [
|
||||
[
|
||||
{ text: '文件統計', callback_data: `count ${fid}` },
|
||||
{ text: '開始複製', callback_data: `copy ${fid}` }
|
||||
]
|
||||
].concat(gen_bookmark_choices(fid))
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
// console.log(gen_bookmark_choices())
|
||||
function gen_bookmark_choices (fid) {
|
||||
let level = 1
|
||||
if (BUTTON_LEVEL > 2){
|
||||
level = 2
|
||||
}else{
|
||||
level = BUTTON_LEVEL
|
||||
}
|
||||
const gen_choice = v => ({text: `複製到 ${v.alias}`, callback_data: `copy ${fid} ${v.alias}`})
|
||||
const records = db.prepare('select * from bookmark').all()
|
||||
db.close()
|
||||
const result = []
|
||||
for (let i = 0; i < records.length; i++) {
|
||||
const line = [gen_choice(records[i])]
|
||||
for(let j = 0; j < level-1; j ++){
|
||||
if (records[i+1]) line.push(gen_choice(records[i+1]))
|
||||
i++
|
||||
}
|
||||
result.push(line)
|
||||
}
|
||||
return result
|
||||
}
|
||||
|
||||
async function send_all_tasks (chat_id) {
|
||||
let records = db.prepare('select id, status, ctime from task').all()
|
||||
if (!records.length) return sm({ chat_id, text: '数据库中没有任务记录' })
|
||||
if (!records.length) return sm({ chat_id, text: '資料庫中沒有任務記錄' })
|
||||
const tb = new Table({ style: { head: [], border: [] } })
|
||||
const headers = ['ID', 'status', 'ctime']
|
||||
records = records.map(v => {
|
||||
@ -59,69 +161,103 @@ async function send_all_tasks (chat_id) {
|
||||
return axins.post(url, {
|
||||
chat_id,
|
||||
parse_mode: 'HTML',
|
||||
text: `所有拷贝任务:\n<pre>${text}</pre>`
|
||||
}).catch(async err => {
|
||||
const description = err.response && err.response.data && err.response.data.description
|
||||
if (description && description.includes('message is too long')) {
|
||||
text: `所有拷貝任務:\n<pre>${text}</pre>`
|
||||
}).catch(err => {
|
||||
// const description = err.response && err.response.data && err.response.data.description
|
||||
// if (description && description.includes('message is too long')) {
|
||||
if (true) {
|
||||
const text = [headers].concat(records).map(v => v.join('\t')).join('\n')
|
||||
return sm({ chat_id, parse_mode: 'HTML', text: `所有拷贝任务:\n<pre>${text}</pre>` })
|
||||
return sm({ chat_id, parse_mode: 'HTML', text: `所有拷貝任務:\n<pre>${text}</pre>` })
|
||||
}
|
||||
console.error(err)
|
||||
})
|
||||
}
|
||||
|
||||
async function send_task_info ({ task_id, chat_id }) {
|
||||
async function get_task_info (task_id) {
|
||||
const record = db.prepare('select * from task where id=?').get(task_id)
|
||||
if (!record) return sm({ chat_id, text: '数据库不存在此任务ID:' + task_id })
|
||||
|
||||
const gen_link = fid => `<a href="https://drive.google.com/drive/folders/${fid}">${fid}</a>`
|
||||
if (!record) return {}
|
||||
const { source, target, status, copied, mapping, ctime, ftime } = record
|
||||
const folder_mapping = mapping && mapping.trim().split('\n')
|
||||
const new_folder = folder_mapping && folder_mapping[0].split(' ')[1]
|
||||
const { summary } = db.prepare('select summary from gd where fid=?').get(source) || {}
|
||||
const { file_count, folder_count, total_size } = summary ? JSON.parse(summary) : {}
|
||||
const copied_files = copied ? copied.trim().split('\n').length : 0
|
||||
const copied_folders = mapping ? (mapping.trim().split('\n').length - 1) : 0
|
||||
let text = '任务编号:' + task_id + '\n'
|
||||
text += '源ID:' + gen_link(source) + '\n'
|
||||
text += '目的ID:' + gen_link(target) + '\n'
|
||||
text += '任务状态:' + status + '\n'
|
||||
text += '创建时间:' + dayjs(ctime).format('YYYY-MM-DD HH:mm:ss') + '\n'
|
||||
text += '完成时间:' + (ftime ? dayjs(ftime).format('YYYY-MM-DD HH:mm:ss') : '未完成') + '\n'
|
||||
text += '目录进度:' + copied_folders + '/' + (folder_count === undefined ? '未知数量' : folder_count) + '\n'
|
||||
text += '文件进度:' + copied_files + '/' + (file_count === undefined ? '未知数量' : file_count) + '\n'
|
||||
text += '总大小:' + (total_size || '未知大小')
|
||||
return sm({ chat_id, text, parse_mode: 'HTML' })
|
||||
const copied_folders = folder_mapping ? (folder_mapping.length - 1) : 0
|
||||
let text = '任務ID:' + task_id + '\n'
|
||||
const folder_name = await get_folder_name(source)
|
||||
text += '源資料夾:' + gen_link(source, folder_name) + '\n'
|
||||
text += '目的位置:' + gen_link(target) + '\n'
|
||||
text += '新資料夾:' + (new_folder ? gen_link(new_folder) : '尚未創建') + '\n'
|
||||
text += '任務狀態:' + status + '\n'
|
||||
text += '創建時間:' + dayjs(ctime).format('YYYY-MM-DD HH:mm:ss') + '\n'
|
||||
text += '完成時間:' + (ftime ? dayjs(ftime).format('YYYY-MM-DD HH:mm:ss') : '未完成') + '\n'
|
||||
var pct = copied_folders/(folder_count === undefined ? '未知數量' : folder_count)*100
|
||||
pct = pct.toFixed(2);
|
||||
text += '目錄進度:' + copied_folders + '/' + (folder_count === undefined ? '未知數量' : folder_count) + ' - ' + pct + '%\n'
|
||||
pct = copied_files/(file_count === undefined ? '未知數量' : file_count)*100
|
||||
pct = pct.toFixed(2);
|
||||
text += '文件進度:' + copied_files + '/' + (file_count === undefined ? '未知數量' : file_count) + ' - ' + pct + '%\n'
|
||||
text += '合計大小:' + (total_size || '未知大小')
|
||||
const total_count = (folder_count || 0) + (file_count || 0)
|
||||
return { text, status, total_count }
|
||||
}
|
||||
|
||||
async function tg_copy ({ fid, target, chat_id }) { // return task_id
|
||||
async function send_task_info ({ task_id, chat_id }) {
|
||||
const { text, status, folder_count } = await get_task_info(task_id)
|
||||
if (!text) return sm({ chat_id, text: '資料庫查無此任務ID:' + task_id })
|
||||
const url = `https://api.telegram.org/bot${tg_token}/sendMessage`
|
||||
let message_id
|
||||
try {
|
||||
const { data } = await axins.post(url, { chat_id, text, parse_mode: 'HTML' })
|
||||
message_id = data && data.result && data.result.message_id
|
||||
} catch (e) {
|
||||
console.log('fail to send message to tg', e.message)
|
||||
}
|
||||
// get_task_info 在task目录数超大时比较吃cpu,如果超1万就不每10秒更新了,以后如果把mapping 也另存一张表可以取消此限制
|
||||
if (!message_id || status !== 'copying' || folder_count > 10000) return
|
||||
const loop = setInterval(async () => {
|
||||
const url = `https://api.telegram.org/bot${tg_token}/editMessageText`
|
||||
const { text, status } = await get_task_info(task_id)
|
||||
if (status !== 'copying') clearInterval(loop)
|
||||
axins.post(url, { chat_id, message_id, text, parse_mode: 'HTML' }).catch(e => console.error(e.message))
|
||||
}, 10 * 1000)
|
||||
}
|
||||
|
||||
async function tg_copy ({ fid, target, chat_id, update }) { // return task_id
|
||||
target = target || DEFAULT_TARGET
|
||||
if (!target) {
|
||||
sm({ chat_id, text: '请输入目的地ID或先在config.js里设置默认复制目的地ID(DEFAULT_TARGET)' })
|
||||
sm({ chat_id, text: '請輸入目的地ID或先在config.js中設定預設複製的目的地ID(DEFAULT_TARGET)' })
|
||||
return
|
||||
}
|
||||
|
||||
let record = db.prepare('select id, status from task where source=? and target=?').get(fid, target)
|
||||
if (record) {
|
||||
if (record.status === 'copying') {
|
||||
sm({ chat_id, text: '已有相同源ID和目的ID的任务正在进行,查询进度可输入 /task ' + record.id })
|
||||
sm({ chat_id, text: '已有相同來源ID和目的ID的任務正在進行,查詢進度可輸入 /task ' + record.id })
|
||||
return
|
||||
} else if (record.status === 'finished') {
|
||||
sm({ chat_id, text: '有相同源ID和目的ID的任务已复制完成,如需重新复制请更换目的地' })
|
||||
return
|
||||
sm({ chat_id, text: `檢測到已存在的任務 ${record.id},開始繼續拷貝` })
|
||||
}
|
||||
}
|
||||
|
||||
real_copy({ source: fid, target, not_teamdrive: true, service_account: true, is_server: true })
|
||||
.then(folder => {
|
||||
real_copy({ source: fid, update, target, service_account: !USE_PERSONAL_AUTH, is_server: true })
|
||||
.then(async info => {
|
||||
if (!record) record = {} // 防止无限循环
|
||||
if (!folder) return
|
||||
const link = 'https://drive.google.com/drive/folders/' + folder.id
|
||||
sm({ chat_id, text: `${fid} 复制完成,新文件夹链接:${link}` })
|
||||
if (!info) return
|
||||
const { task_id } = info
|
||||
const { text } = await get_task_info(task_id)
|
||||
sm({ chat_id, text, parse_mode: 'HTML' })
|
||||
})
|
||||
.catch(err => {
|
||||
const task_id = record && record.id
|
||||
if (task_id){
|
||||
db.prepare('update task set status=? where id=?').run('error', task_id)
|
||||
db.close()
|
||||
}
|
||||
if (!record) record = {}
|
||||
console.error('复制失败', fid, '-->', target)
|
||||
console.error('複製失敗', fid, '-->', target)
|
||||
console.error(err)
|
||||
sm({ chat_id, text: '复制失败,失败消息:' + err.message })
|
||||
sm({ chat_id, text: '複製失敗,失敗訊息:' + err.message })
|
||||
})
|
||||
|
||||
while (!record) {
|
||||
@ -141,33 +277,39 @@ function reply_cb_query ({ id, data }) {
|
||||
const url = `https://api.telegram.org/bot${tg_token}/answerCallbackQuery`
|
||||
return axins.post(url, {
|
||||
callback_query_id: id,
|
||||
text: '开始执行 ' + data
|
||||
text: '開始執行 ' + data
|
||||
})
|
||||
}
|
||||
|
||||
async function send_count ({ fid, chat_id }) {
|
||||
const table = await gen_count_body({ fid, type: 'tg', service_account: true })
|
||||
async function send_count ({ fid, chat_id, update }) {
|
||||
sm({ chat_id, text: `開始獲取 ${fid} 所有檔案資訊,請稍後,建議統計完成前先不要開始複製,因为複製也需要先獲取來源資料夾資訊` })
|
||||
const table = await gen_count_body({ fid, update, type: 'tg', service_account: !USE_PERSONAL_AUTH })
|
||||
if (!table) return sm({ chat_id, parse_mode: 'HTML', text: gen_link(fid) + ' 資訊獲取失敗' })
|
||||
const url = `https://api.telegram.org/bot${tg_token}/sendMessage`
|
||||
const gd_link = `https://drive.google.com/drive/folders/${fid}`
|
||||
const name = await get_folder_name(fid)
|
||||
return axins.post(url, {
|
||||
chat_id,
|
||||
parse_mode: 'HTML',
|
||||
// todo 输出文件名
|
||||
text: `<pre>${gd_link}
|
||||
text: `<pre>源資料夾名稱:${name}
|
||||
源連結:${gd_link}
|
||||
${table}</pre>`
|
||||
}).catch(async err => {
|
||||
const description = err.response && err.response.data && err.response.data.description
|
||||
if (description && description.includes('message is too long')) {
|
||||
const smy = await gen_count_body({ fid, type: 'json', service_account: true })
|
||||
// const description = err.response && err.response.data && err.response.data.description
|
||||
// const too_long_msgs = ['request entity too large', 'message is too long']
|
||||
// if (description && too_long_msgs.some(v => description.toLowerCase().includes(v))) {
|
||||
if (true) {
|
||||
const smy = await gen_count_body({ fid, type: 'json', service_account: !USE_PERSONAL_AUTH })
|
||||
const { file_count, folder_count, total_size } = JSON.parse(smy)
|
||||
return sm({
|
||||
chat_id,
|
||||
parse_mode: 'HTML',
|
||||
text: `文件统计:<a href="https://drive.google.com/drive/folders/${fid}">${fid}</a>\n<pre>
|
||||
表格太长超出telegram消息限制,只显示概要:
|
||||
文件总数:${file_count}
|
||||
目录总数:${folder_count}
|
||||
合计大小:${total_size}
|
||||
text: `連結:<a href="https://drive.google.com/drive/folders/${fid}">${fid}</a>\n<pre>
|
||||
表格太長超出telegram訊息限制,僅顯示概要:
|
||||
目錄名稱:${name}
|
||||
文件總數:${file_count}
|
||||
目錄總數:${folder_count}
|
||||
合計大小:${total_size}
|
||||
</pre>`
|
||||
})
|
||||
}
|
||||
@ -178,25 +320,33 @@ ${table}</pre>`
|
||||
function sm (data) {
|
||||
const url = `https://api.telegram.org/bot${tg_token}/sendMessage`
|
||||
return axins.post(url, data).catch(err => {
|
||||
console.error('fail to post', url, data)
|
||||
console.error(err)
|
||||
// console.error('fail to post', url, data)
|
||||
console.error('fail to send message to tg:', err.message)
|
||||
})
|
||||
}
|
||||
|
||||
function extract_fid (text) {
|
||||
text = text.replace(/^\/count/, '').replace(/^\/copy/, '').trim()
|
||||
text = text.replace(/^\/count/, '').replace(/^\/copy/, '').replace(/\\/g, '').trim()
|
||||
const [source, target] = text.split(' ').map(v => v.trim())
|
||||
if (validate_fid(source)) return source
|
||||
try {
|
||||
if (!text.startsWith('http')) text = 'https://' + text
|
||||
const u = new URL(text)
|
||||
if (u.pathname.includes('/folders/')) {
|
||||
const reg = /\/folders\/([a-zA-Z0-9_-]{10,100})/
|
||||
const reg = /[^/?]+$/
|
||||
const match = u.pathname.match(reg)
|
||||
return match && match[1]
|
||||
return match && match[0]
|
||||
}
|
||||
return u.searchParams.get('id')
|
||||
} catch (e) {
|
||||
return ''
|
||||
}
|
||||
}
|
||||
|
||||
function extract_from_text (text) {
|
||||
const reg = /https?:\/\/drive.google.com\/[^\s]+/g
|
||||
const m = text.match(reg)
|
||||
return m && extract_fid(m[0])
|
||||
}
|
||||
|
||||
module.exports = { send_count, send_help, sm, extract_fid, reply_cb_query, send_choice, send_task_info, send_all_tasks, tg_copy, extract_from_text, get_target_by_alias, send_bm_help, send_all_bookmarks, set_bookmark, unset_bookmark }
|
||||
|
||||
Loading…
Reference in New Issue
Block a user